

What is Data Fabric?
Understanding Data Management and Integration for Unified Data Storage
Data fabric is a unified architecture that integrates an organization’s processes, data, and analytics, and more into an interconnected framework. It standardizes data governance and security practices across on-prem and cloud environments — including hybrid and multi-cloud.
Traditional data integration methods rely on point-to-point connections and rigid architectures. However, this framework is more flexible and dynamic. It lets organizational data flow freely across the entire landscape, while ensuring data security.
Unlike traditional ETL pipelines, data fabric supports modern data integration techniques that adapt to changing business needs and deliver data more efficiently.
The data fabric architecture enables data discovery in a distributed environment. This architecture connects various data sources, including cloud-based data warehouses, on-premise databases, and SaaS applications, to create a centralized data fabric that allows seamless data access, integration, and processing. This integration makes combining disparate data sources, applications, and infrastructure easier for data virtualization.
This, in turn, simplifies data management and accelerates data processing, which enables organizations to gain insights and make informed decisions faster with specific data. Data engineers and data scientists can leverage this architecture to streamline their workflows and improve data analytics capabilities.
Additionally, data fabric architecture can easily scale to accommodate increasing data volumes. It reduces the operational cost and complexity of physically integrating and centralizing data.
Components of the Data Fabric Architecture
A data fabric isn’t a single product—it’s an architectural approach built from connected capabilities. While every implementation looks a little different, most fabrics include a few common building blocks:
Data Ingestion and Integration
This component brings data from cloud, on-premises, and edge systems together in real time through streaming data and change data capture, or in batch for larger transfers.
Metadata Management
This process captures and uses active metadata to understand what data exists, how it relates to other assets, and how it should be governed. Metadata acts as the foundation for automation and intelligence across the fabric. It helps automate data integration and reduce manual effort.
Data Curation and Transformation
Data is cleaned, enriched, and prepared from its raw state to make it accurate, consistent, and ready for analysis or operational use in this component. This process often combines data from various sources to create higher-quality datasets.
Orchestration and Delivery
Pipelines are coordinated, and the right data flows are delivered reliably to the right users and systems, without manual hand-offs or brittle connections.
Access and Consumption
Governed, self-service access is provided for analysts, data scientists, and applications, so teams can use trusted data without creating new silos.
Taken together, these components create a unified fabric that adapts to changing business needs without requiring every dataset to be moved into a single repository.
How Data Fabric Works
A data fabric connects distributed data sources through an intelligent, metadata-driven layer that creates a unified view of data across on-prem, cloud, and hybrid environments—without requiring everything to be centralized.
By automating discovery, governance, and orchestration, the fabric can include data from both structured and unstructured sources and deliver trusted datasets to users and systems. This approach enables teams to analyze data in real time while maintaining consistency, security, and control as data changes.
Why Use a Data Fabric Solution?
According to IBM, up to 68% of the average business data is not analyzed. Additionally, up to 82% of companies run into integration problems due to siloed data and different data types coming from various sources. If you’re a data-driven organization, this is not ideal.
“Fabric” refers to the integrated layer of data and connecting processes across all data environments — including hybrid and multi-cloud platforms.
With a cohesive data fabric, businesses can better manage their data. They can use connected data, metadata, and data analytics to extract maximum value from data in real time. The most important part is that the improved data quality makes analytics more effective.
Using an automated data fabric is the way to go if you’re looking for a modern and efficient way to manage your data. Its cohesive visibility gives you a clear and comprehensive view of your data landscape in real time. This simplifies the data management process and speeds up data processing, enabling you to make faster and better-informed decisions.
Using data fabric solutions can help with easy scaling up to accommodate the ever-increasing amount and variety of data that businesses generate today — helping them become more productive, make better decisions, and stay ahead of the competition. Using a fabric also gives users secure, compliant access to the right quality data to perform their data tasks.
Benefits of a Data Fabric
Modern data environments are complex. By weaving together continuous analytics, automated technologies, AI models, and machine learning across complex data environments, data fabric can help enterprises boost data trust, make better decisions, and drive digital transformation. Here’s how:
Enhanced Data Accessibility and Insights
A unified infrastructure allows for better data visibility and insights. Data fabric provides your organization with a unified and integrated view of its data assets. That enables stakeholders to access, analyze, and act upon data more efficiently and effectively. Decision-makers get timely and actionable insights, which drive better decision-making, innovation, and competitive advantage.
Improved Operational Efficiency and Agility
Data fabric simplifies data integration, governance, and management processes to reduce complexity and inefficiencies in data operations. Improved data access and control drastically streamlines data management initiatives, giving time back to governance teams. This enables your organization to respond more quickly to changing business needs, scale data initiatives, and drive operational excellence and agility.
Accelerated Innovation and Time-to-Value
A data fabric enables you to better protect and reduce the cost of maintaining and managing data — particularly in multi-cloud environments. Your business can unlock the full potential of its data assets to fuel innovation and drive new business opportunities. It democratizes data access and fosters a culture of experimentation and collaboration. That’s how the data architecture empowers teams to innovate, iterate, and deliver value to customers faster and more effectively.
Enhanced Privacy and Security Compliance
Data fabric incorporates robust governance, security, and compliance mechanisms to ensure the privacy, integrity, and confidentiality of sensitive data assets. It helps you implement access controls, encryption, and data masking techniques to protect data at rest and in transit. Moreover, data fabric enables your organization to enforce regulatory compliance with data privacy laws such as GDPR, CCPA, and HIPAA by providing visibility into data lineage, usage, and consent management.
Data Fabric vs Data Mesh
Data mesh describes another data management process that is often confused with data fabric, but tackles the problem of distributed data differently. While data fabric takes a universal interconnectivity approach — weaving together a continuous, unified infrastructure for data management — data mesh is a centrally created architecture for use across distributed data silos. However, a data mesh does not necessarily address the issue of interoperability.
Ultimately, both approaches make data more accessible and secure, but data fabric alone focuses on a holistic, interactive architecture.
Data Fabric vs Data Lake
Data fabric and data lake are two different approaches to managing enterprise data. While they may seem at odds, they can actually coexist quite well. A data lake is a centralized repository that can be used to store and analyze structured and unstructured data. In contrast, a data fabric is a distributed architecture that seamlessly integrates and shares data across multiple sources and platforms.
Data lakes are great for storing and processing large amounts of data. In practice, this means that they can act as the primary data source for a data fabric. Data fabrics, on the other hand, help ensure that this new data is accessible and available to users and applications. They provide the necessary connectivity and agility to access data and analyze it in real time.
For example, a data lake could store and process large amounts of customer data, while a data fabric could integrate this data with other sources, such as social media, to provide a complete view of customer behavior.
These data lakes and fabrics facilitate the creation and delivery of data products. By leveraging them, organizations can gain greater insights and efficiencies from their real-time data, while ensuring that it is accessible and available to those who need it.
Relationship Between Data Fabric and Data Integration
A data fabric depends on automated, AI-driven integration that improves over time. An effective fabric automates multiple integration styles, scales data management, streamlines data delivery across an enterprise, reduces storage costs, and maximizes performance. The resulting architecture:
- makes difficult-to-locate data easily accessible in multi-cloud and hybrid environments
- eliminates data silos
- eliminates multiple and manual tools
- future-proofs data management practices, as new sources are added
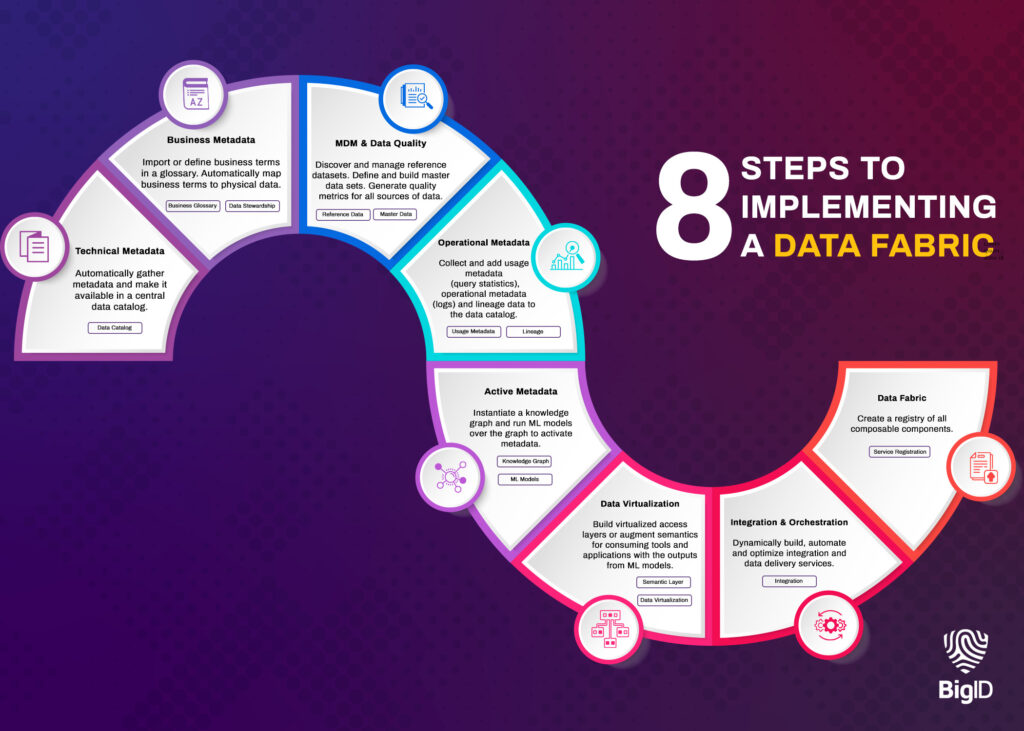
BigID and Your Enterprise Data Fabric — How It Works
BigID introduces an ML-driven, semantic approach to enabling a data fabric for your organization. Here’s how the platform helps build a seamless data fabric solution to future-proof digital transformation and data management practices for your business.
Cover all your data — everywhere: Automatically connect to all data types — including structured and unstructured data — in on-prem, multi-cloud, and hybrid environments.
Get a single view of metadata: With an unmatched discovery foundation, BigID can scan all your data, everywhere, to create a unified data catalog — and a single view of all your metadata.
Classify data based on deep learning: BigID specializes in classification methods that go beyond pattern-based discovery. Automatically classify more data types with NLP and NER — and AI insight based on deep learning within the data management architecture.
Exchange and share data: Enable collaboration and data sharing among employees in real time.
Add context to data: Layer technical, business, and operational metadata to see data attributes and relationships.
Leverage active metadata for better interoperability: With ML-augmented metadata, gain insights from your metadata, empower your organization to take action on it, and drive better business decisions.
Check out a demo to see BigID in action — and find out how we can help you build an ML-driven data fabric.
