Fuzzy-Klassifizierung
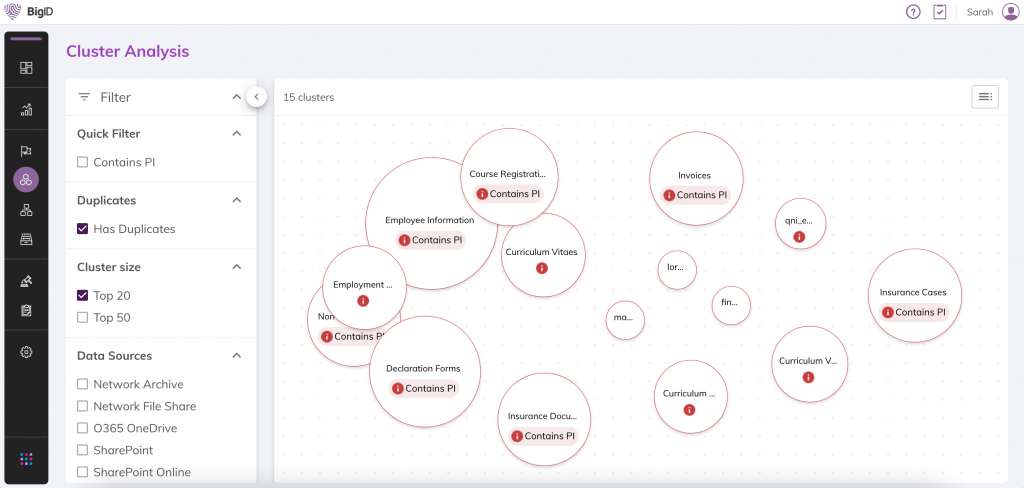
Ähnliche, doppelte und redundante Daten in Ihrer gesamten Datenlandschaft automatisch identifizieren. Schnelle Filterung nach Sensibilität, Datenquellen, Attributen und Duplikaten.
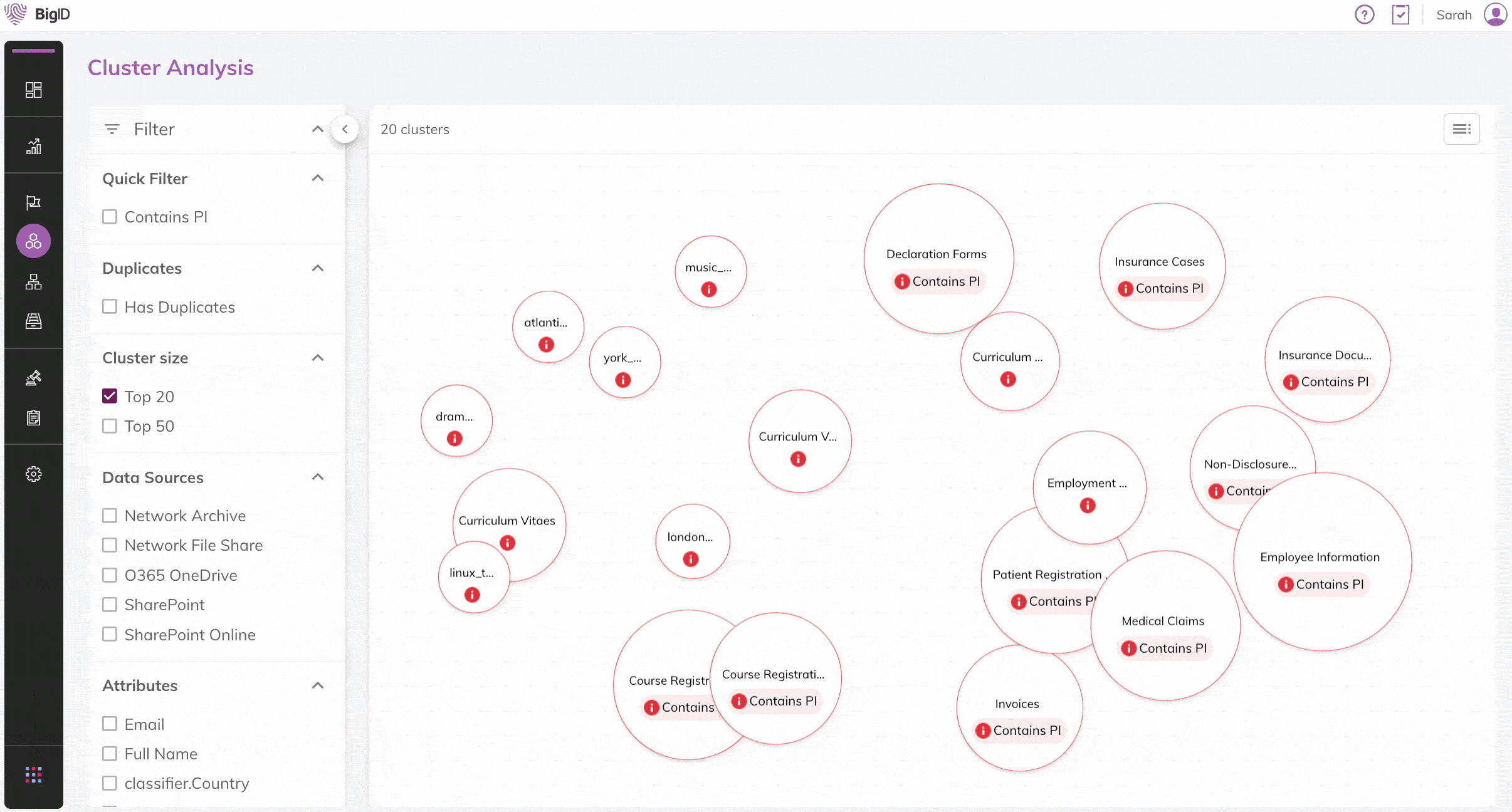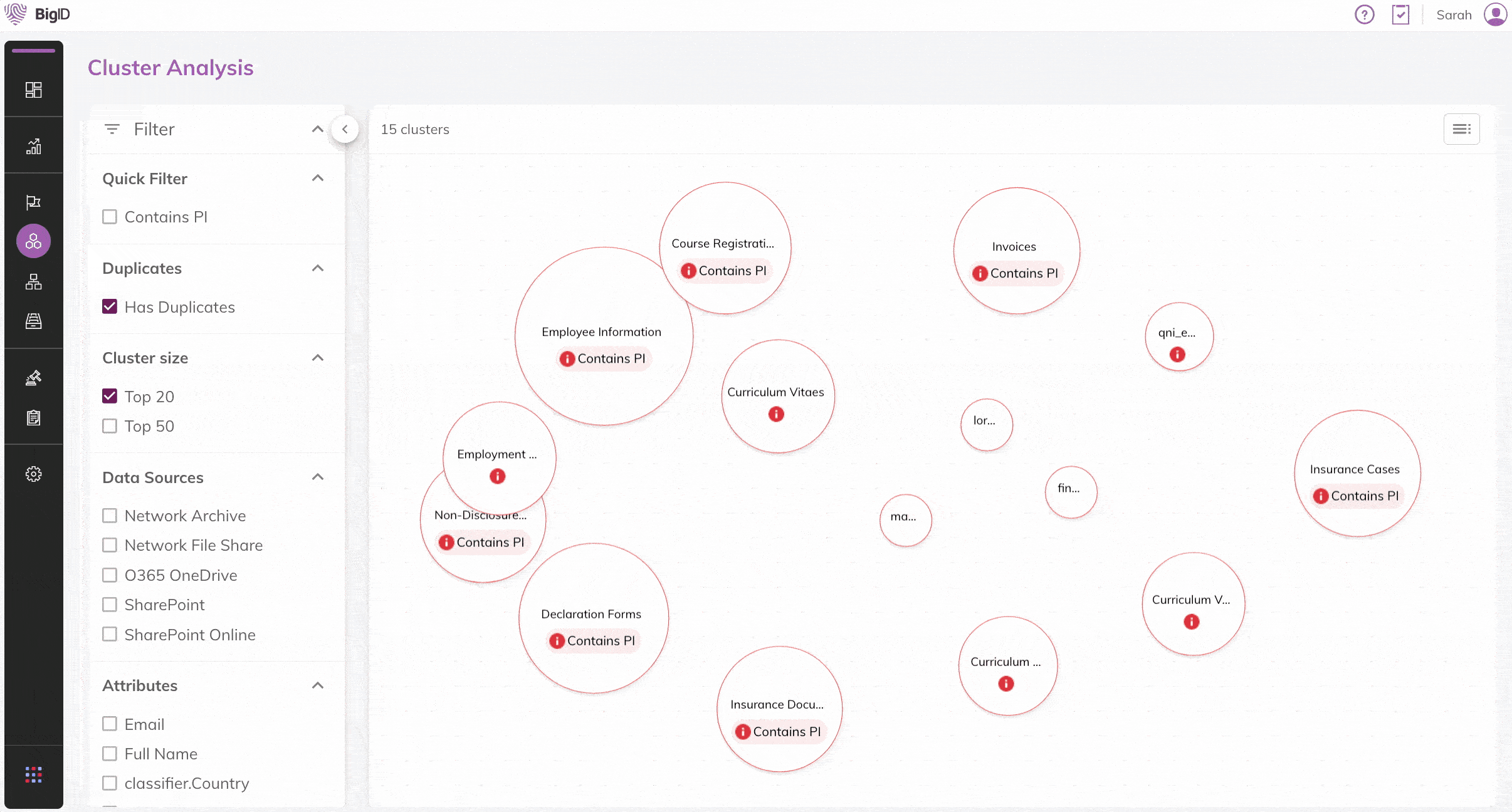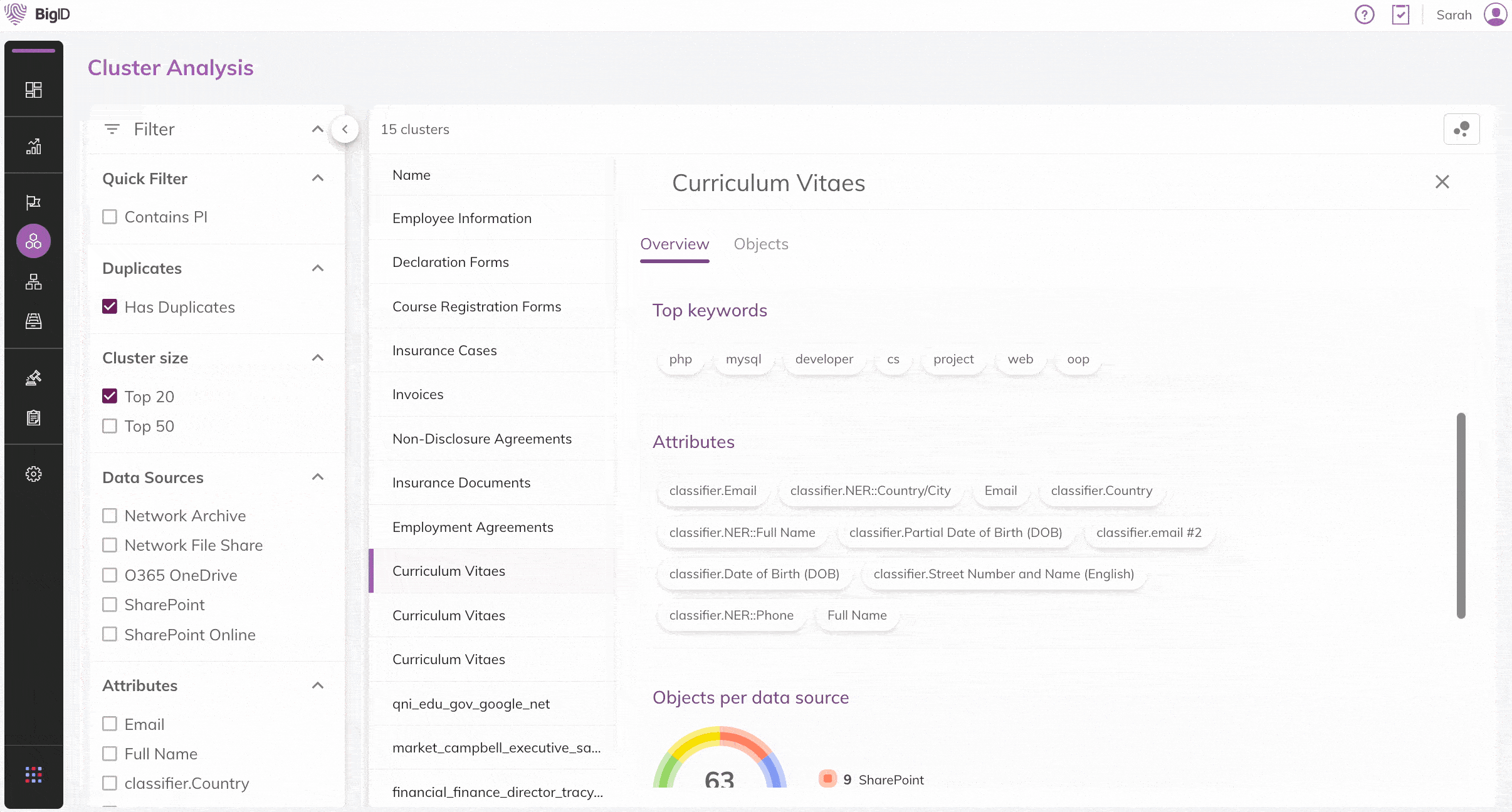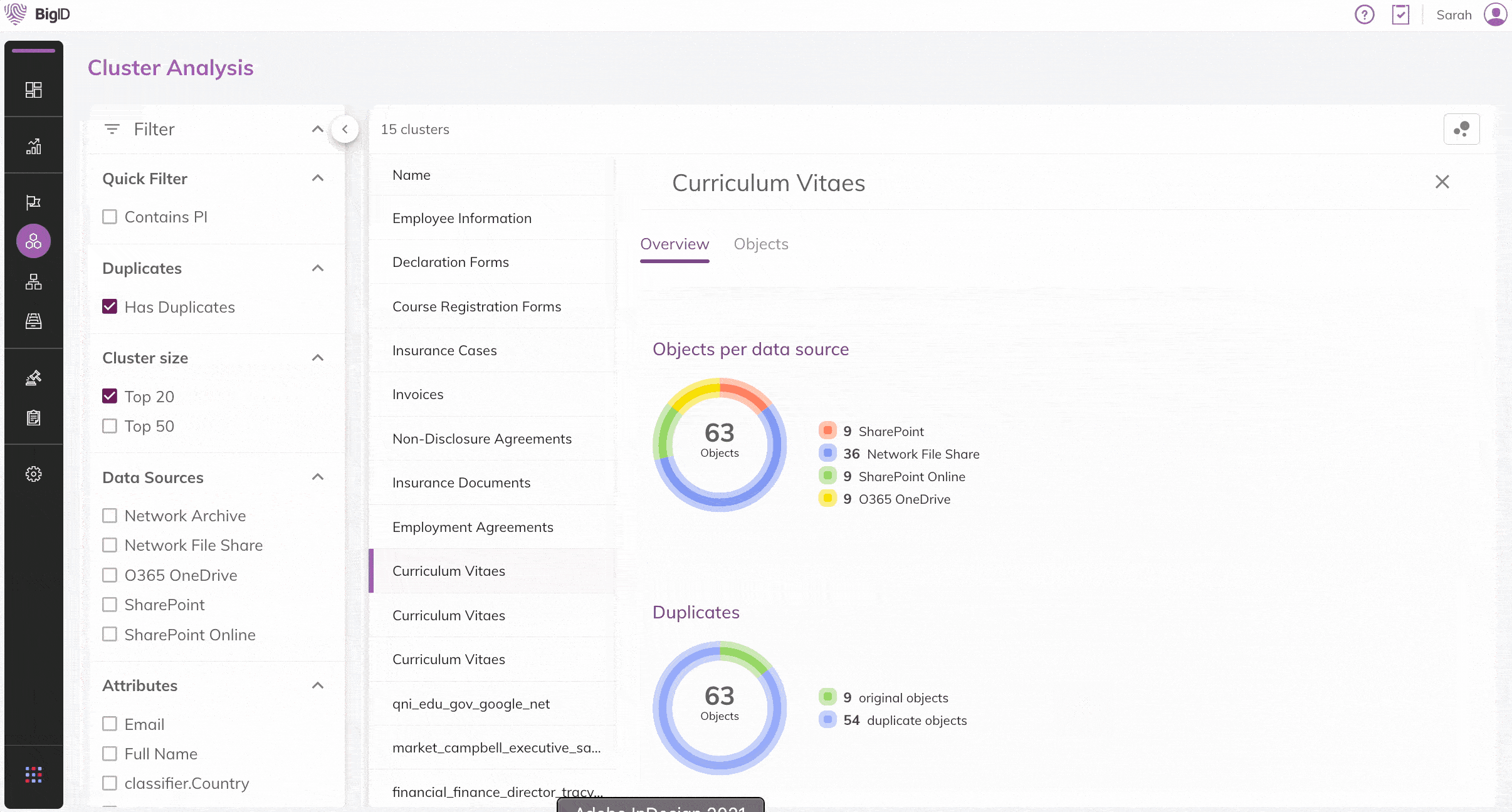
Unüberwachte Machine Learning (ML)-Verfahren anwenden, um ähnliche Inhalte in Dateien schnell zu identifizieren. Transparenz & Einblick in Ihre Daten
–unabhängig davon, wo diese sich befinden: On-Premise, in der Cloud oder in Hybrid-Umgebungen
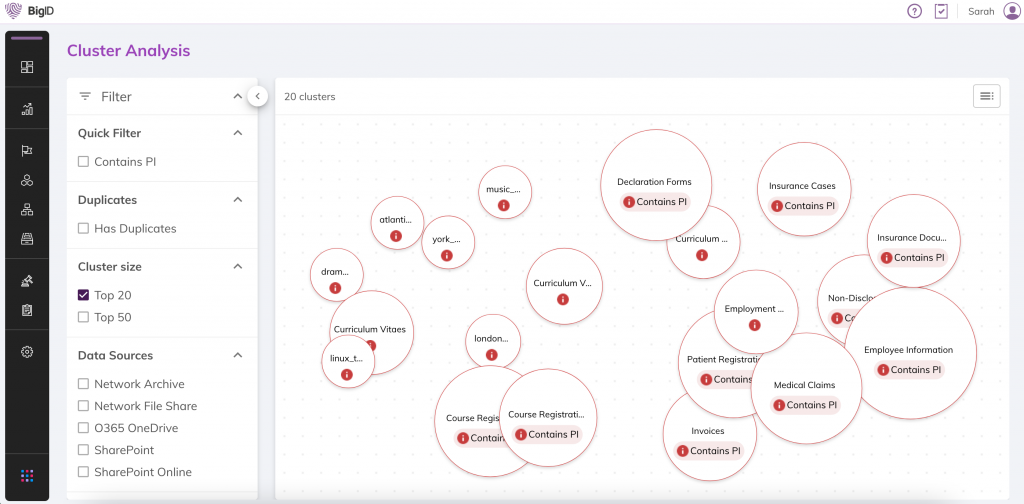
Datenminimierung
Identifizieren Sie, welche Daten minimiert werden sollen und wo sich Duplikate sowie redundante Daten befinden. Priorisieren Sie Daten mit hohem Risiko.
Ähnliche und doppelte Daten visualisieren und dadurch Erkenntnisse zu großen Datensätzen in Ihrer Datenumgebung gewinnen, um Daten strategisch zu minimieren.
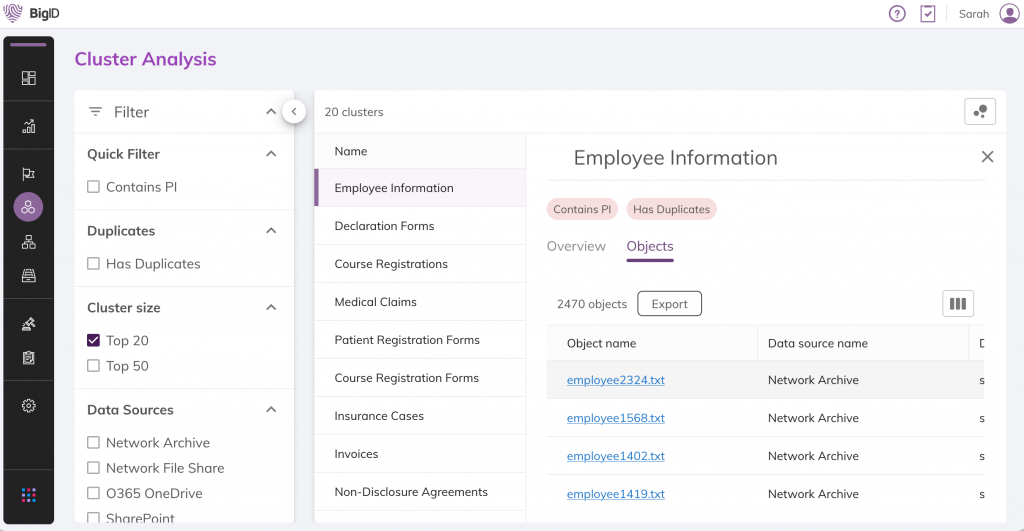
Cloud-Migrationen beschleunigen
Mit intelligenter Datenrationalisierung Cloud-Migrationen beschleunigen (einschließlich O365, AWS und GCP). Verbesserung der Datenhygiene, Kostensenkung durch Konsolidierung redundanter Daten und auf einem Blick erkennen, was in die Cloud verlagert werden sollte und was nicht.