

Can you identify and manage all of your data by its sensitivity or criticality? If you can’t confidently answer that with an unequivocal “yes”, you’re not alone. With the accelerating growth of public, private, or hybrid cloud models, data is being proliferated throughout the network at unbelievable rates. It’s no wonder IT teams struggle to get the basics right of knowing what data they have, let alone understand the sensitive nature of it.
Many data privacy, security, and governance leaders we speak with today say they don’t have a basic understanding of data sensitivity across their environment. Even if they are able to grasp a solid picture of what data they have, they typically lack the contextual depth needed to make proactive decisions. Unfortunately, organizations rely on a patchwork of legacy solutions to cobble up a fragmented picture of what they have and how it’s classified.
IT leaders not only need complete visibility and control of their data, they must understand their data in the context of sensitivity across a variety of privacy and security-related disciplines. These contextual insights drive actionable decisions that can prevent and protect the organization from malicious threats.
We’re excited to introduce the Advanced Sensitivity Classification feature, enabling customers to easily determine the sensitivity of their data with certainty, and at scale:
- Automatically discover sensitive data across your environment
- Obtain insight about its sensitivity or criticality level
- Take corrective actions to proactively drive decision-making and mitigate cyber risk.
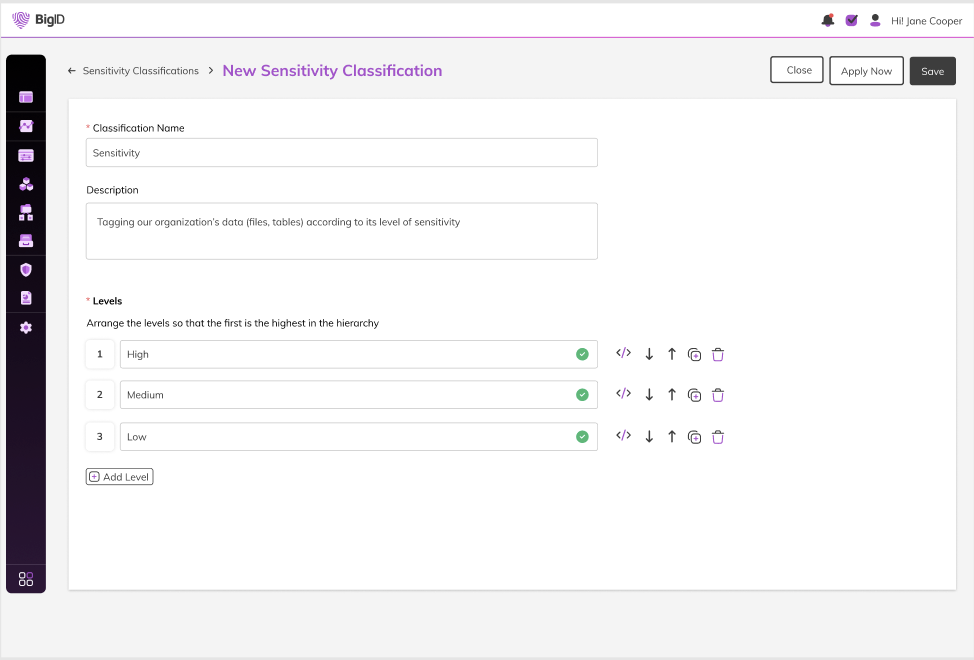
Know & Manage the Sensitivity of Your Data
Using existing classification capabilities, BigID can provide a breakdown of data that is classified as sensitive versus data that is undefined. The presence of undefined data means that the existing definition of sensitivity may need further refinement to ensure its inclusion of all data. With Advanced Sensitivity Classification, organizations can get more granularity by understanding this data by sensitivity level.
These levels are determined by either out of the box definitions or can be defined individually by your organization’s interpretations. Each level is propagated with a tag; each tag is defined by a collection of rules and attributes that correspond to its level of sensitivity. For example, a sensitivity classification tag of “High” could be defined as social security numbers or personal addresses, while a sensitivity classification tag of “Low” could be defined as something less, such as a customer’s favorite movie.
Advanced sensitivity classification rules can be easily deployed in just a few clicks, and tags are automatically applied to the corresponding data objects. Even better? Organizations can automate this process by automatically applying advanced sensitivity tagging after every scan moving forward.
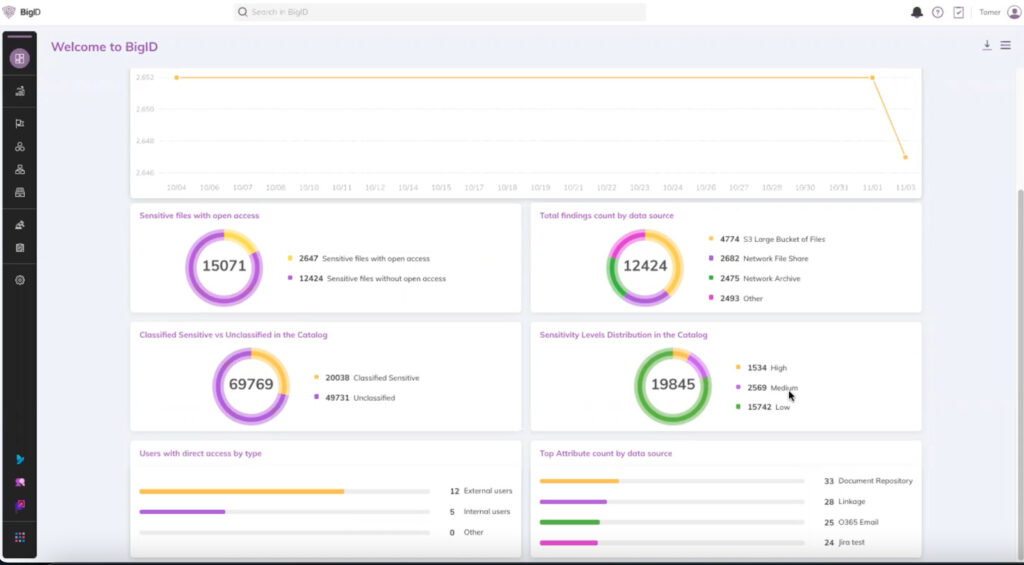
Proactively Drive Action to Mitigate Risk
Advanced Sensitivity Classification goes beyond just visibility: take action by proactively defining and applying policies for better data control.
- Leverage sensitivity tags and define a policy around them, such as triggering an alert to staff when certain sensitivity thresholds are passed.
- When a sensitivity level is met, trigger a specific action such as making an API call, sending an email, or opening a Jira ticket.
- Define workflows, notify the right individuals, and schedule SLAs using BigID’s Data Remediation app.
- Integrate with Microsoft Information Protection (MIP) to complement and streamline your data labeling workflows. Map MIP labels to corresponding BigID labels, and leverage BigID’s labeling capabilities to automatically tag your data objects with MIP labels as well.
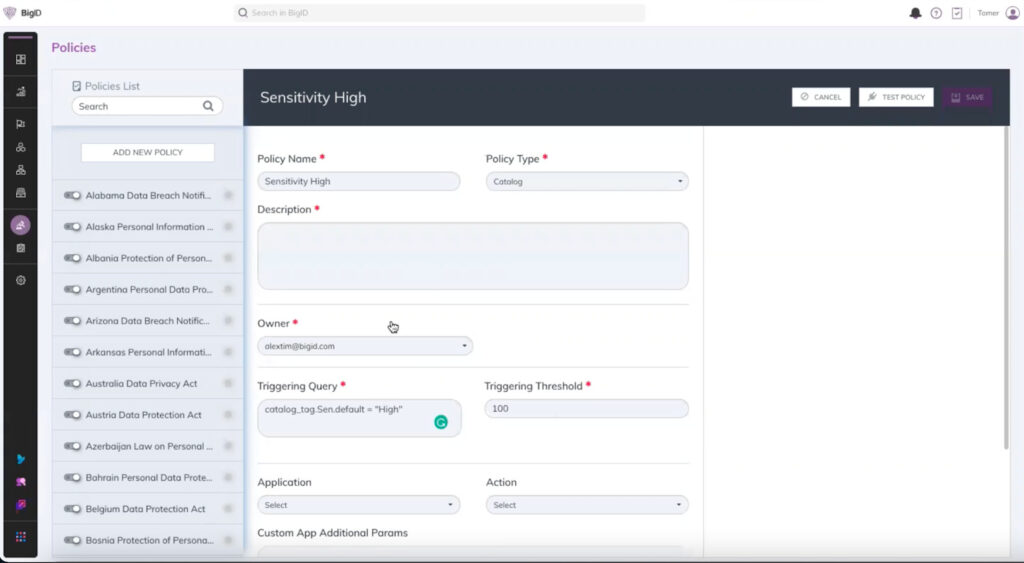
Preview Advanced Sensitivity Classification in action!
BigID helps organizations of all sizes to manage, protect, and get more value out of their data across anywhere it exists – on-prem or in the cloud. Understand the sensitivity nature of your data with Advanced Sensitivity Classification. Get a 1:1 demo with our experts to see it in action today.