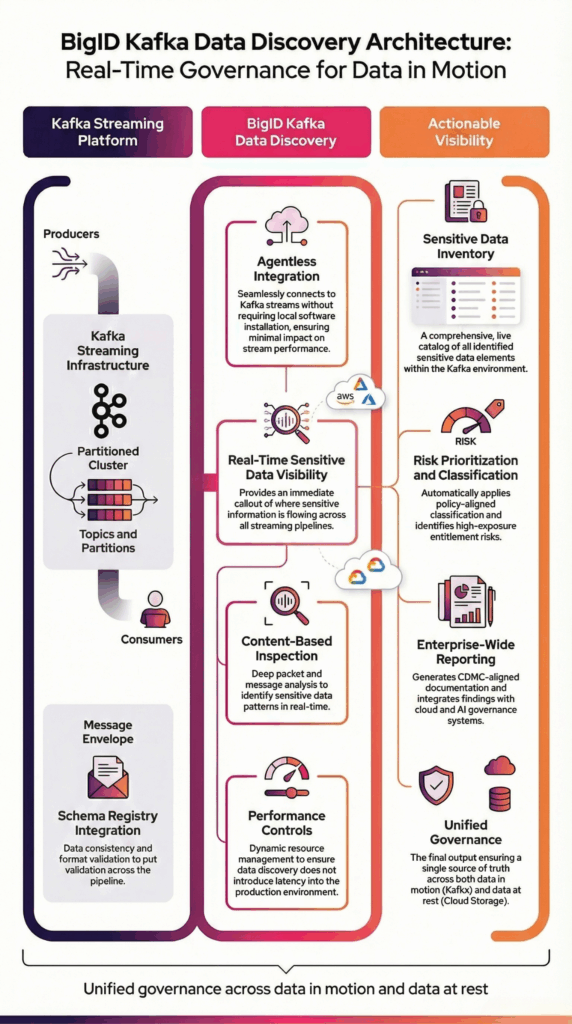
BigID connects securely to Kafka using agentless integration to scan streaming data across topics and partitions. It analyzes message payloads at the content level to accurately identify sensitive and regulated information within real-time data flows.
BigID supports:
- Apache Kafka (Core)
- Confluent Kafka
- Avro serialization with schema registry integration
- Distributed partitions and replicated clusters
BigID performs configurable sampling across poll intervals to align with high-throughput environments while preserving operational performance.
Discovery results integrate with enterprise classification policies, governance workflows, and reporting frameworks to provide unified visibility across streaming and persistent data environments.
This architecture ensures scalable Kafka sensitive data discovery without interrupting production pipelines.