

Third-party container images supercharge Kubernetes and container-based deployments, saving teams weeks of setup and configuration. But convenience comes at a cost: outdated images quickly become security liabilities. Each new CVE discovered in a base layer or dependency can turn yesterday’s image into tomorrow’s attack vector.
Because these images rely on multiple layers and dependencies, they often carry hidden flaws. Researchers continue to uncover new Common Vulnerabilities and Exposures (CVEs) in operating systems and software packages—and every outdated image in use creates an open door for attackers. Failing to update these images doesn’t just introduce risk; it embeds known vulnerabilities directly into your application environment.
The answer isn’t to abandon third-party images—it’s to adopt a proactive security posture.
With BigID, companies can discover every third-party container image in use across their environment. That visibility becomes the foundation for stronger security—enabling teams to scan for new CVEs, assess risk, remediate vulnerabilities, and deploy updated versions with confidence. Regular updates stop being tedious maintenance and become a streamlined, automated practice that safeguards both applications and users.
BigID goes beyond basic discovery: it classifies everything from structured data to code snippets, delivering the visibility needed to see exactly where third-party container images are referenced and when they put applications at risk. That insight empowers teams to act quickly, close security gaps, and maintain resilience.
Getting to Know BigID
This section is dedicated to explaining the parts of the BigID product that are relevant to ensure third-party container image tracking.
Working with BigID entails this general workflow:
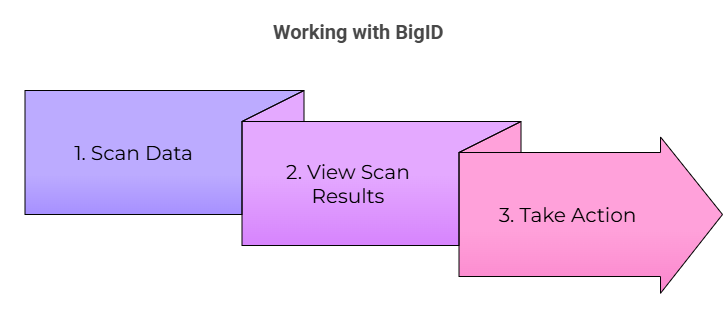
- Scan your data – Connect data sources and analyze their contents.
- View scan results – Catalog data objects, sensitive data findings, risk alerts, and drill into reports.
- Take action on your data – Remediate redundant data, automate compliance, enforce security policies, and more.
BigID scans structured, semi-structured, and unstructured data sources, classifying content using techniques from regex to neural-network NER. Teams can use built-in classifiers or define their own, ensuring precision for everything from common PII to container image references.
With this, it is important to clarify a few terms:
- Data source: A data source is your data repository that BigID scans to give you in-depth data insight. BigID can connect to structured, semi-structured, and unstructured formats.
- Scan: Scanning is the BigID core function that connects to your data sources to extract data intelligence by analyzing data structure, content, and metadata.
- Classifier: Classification is a technique for identifying and categorizing data content by word, sentence patterns and grammatical structures. A classifier is a combination of configurations and approaches that provide an accurate form of classification.
- Classification methods:
- Regex: Regular Expressions detect and classify data by recognizing the syntax pattern of the data’s characters.
- Named Entity Recognition (NER): an advanced neural network-based technique that analyzes text in unstructured data sources, identifying hidden personal data and categorizing content type.
- DOC: The BigID NER service also provides Document (DOC) classifiers. DOC classifiers find document types in unstructured data files. They classify different documents, according to their file content as a whole. Use them to find documents such as boarding passes or CVs in unstructured data sources.
The Solution Architecture
As you’ve probably already noticed in our previous article about Hardcoded Secret Detection with BigID, the Application Security Team at BigID is fond of developing and using serverless architectures. Because BigID is an API based product, the integration with this kind of deployments ensures that the whole solution will be scalable and maintainable. Even a complex workflow can be achieved with this mix of technologies.
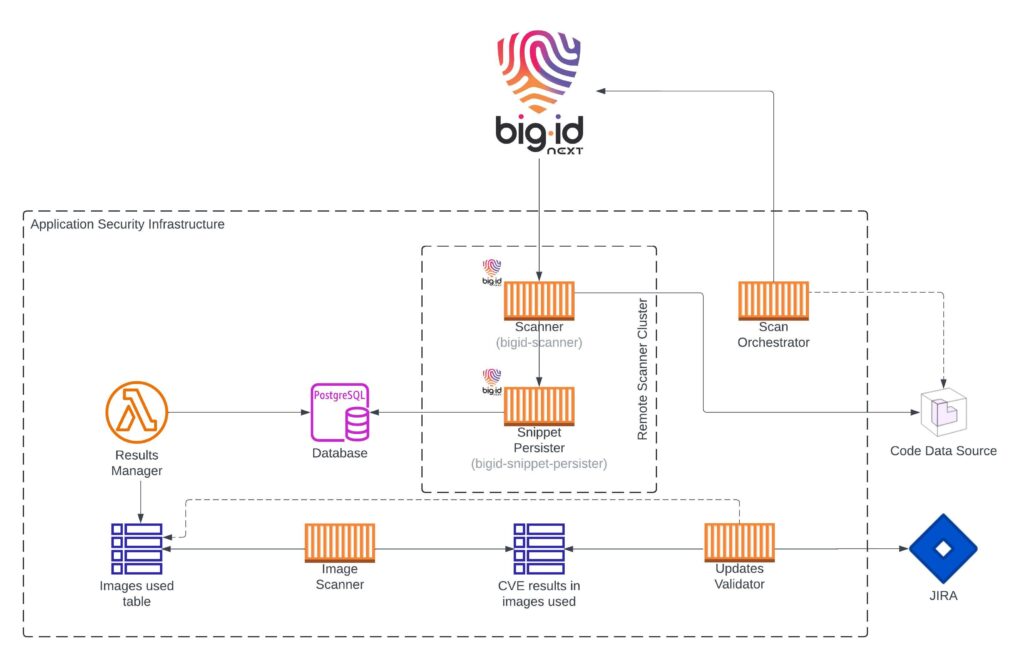
The above workflow is responsible for ensuring a fully automated detection of new tags for third-party images that are available to use.
- The initial trigger is a notification sent to the Scan Orchestrator stating that a new version has been released. This will kick-off the orchestration of the BigID data sources and scans, starting with the creation of a data source dedicated to the Code Data Source (this data source is BigID’s Version Control System) tag corresponding to this new version and the respective scan. This orchestration will ensure that at the end of the scan, the images referenced in BigID’s code are stored in the Database linked to the Snippet Persister.
- The Results Manager component will then fetch the results, normalize and save them to a table for further processing.
- The next step on the flow is to scan these images with a Software Composition Analysis scanner (of your choice) – represented by the Image Scanner – and save the results.
- Finally, the Updates Validator will check for newer versions of the images used and their CVE results, opening Jira tickets if newer versions with less CVEs are found.
Enabling the Image Search
BigID delivers the most advanced data discovery and classification platform, making it a very simple task to find the image references in Infrastructure-as-Code files.
Here is an example of an image reference we’re looking to scan:
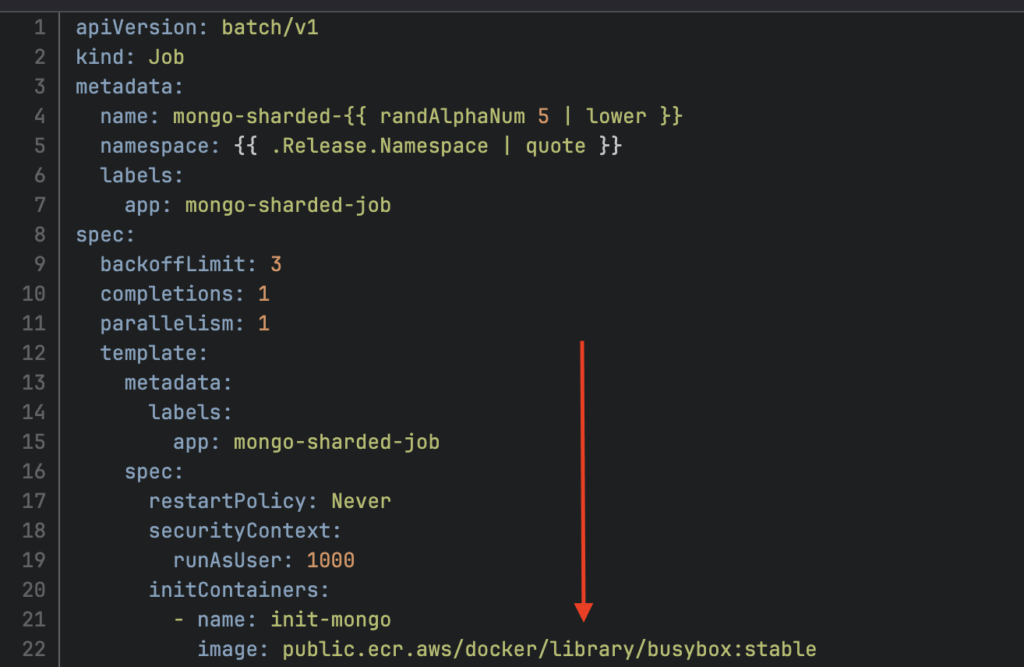
The main enabler is to create a custom classifier based on the following regex:
[^\n]{1,200}name[^\n]{1,200}\n[^#\n]{1,200}image:[ ]*((?:[\w.\-_]+(?::\d+)?\/)?[\w.\-_]+(?:\/[\w.\-_]+)*:[\w.\-_]{1,128})
By applying this classifier to the orchestrated Version Control System tags, we ensure that the images found in the code base have a ~0% rate of false positives.
Classifier Tuning
How else can an Infrastructure-as-Code file reference an image?
BigID’s classifier tuning lets you zero in on image references in Infrastructure-as-Code. Start with precise regex patterns for high accuracy, then broaden to catch edge cases—using BigID’s AI-assisted classification to cut through noise and reduce false positives.
Another Facet of the BigID Snippet Persister
We originally deployed the Remote Scanner Cluster and its associated database to keep sensitive data within a controlled, trusted boundary. In this scenario, however, the setup also creates a simple way to access search results without directly querying the data source—delivering a more decoupled and maintainable architecture.
Turning Container Security Risk Into Resilience
Outdated container images are one of the fastest ways vulnerabilities creep into production. BigID gives security and DevOps teams continuous visibility, proactive alerts, and automated workflows to keep images secure—without slowing innovation. Convenience doesn’t have to come at the cost of security.
To see BigID in action, book a 1:1 demo with our experts.
