

Generative AI (GenAI) is rapidly gaining popularity, but its effectiveness can be hampered by limitations in its training data. This includes a lack of specific information, relevant context, and out-of-date knowledge. Additionally, GenAI models can sometimes generate inaccurate or misleading outputs, known as hallucinations.
Retrieval-Augmented Generation (RAG) offers a compelling solution to address these challenges. RAG leverages Vector Databases (Vector DBs) to provide GenAI models with access to a broader and more relevant knowledge base. However, Vector DBs themselves introduce new considerations and risks. As RAG applications aim to revolutionize customer and employee experiences, vector databases will store sensitive, biased, or restricted metadata, including confidential information. Organizations need robust strategies to identify and manage this sensitive data within their Vector DBs. Proper data cleaning and labeling are essential to maximize the value of RAG and minimize the risk of unauthorized data exposure. Additionally, implementing safeguards against redundant data is crucial for maintaining database efficiency.
BigID & Elasticsearch Vector Database for Secure Retrieval-Augmented Generation (RAG)
By combining BigID’s industry-leading data security and privacy with Elastic’s comprehensive enterprise search capabilities and their Elasticsearch vector database, organizations can build secure and trustworthy RAG applications, supporting the effective use of Generative AI.
Here’s how each solution contributes to a robust and secure RAG architecture:
Elasticsearch Vector Database
The Elastic Search AI platform plays a critical role in RAG architecture.
- Vector Database: With the Elasticsearch vector database developers can implement vector search and semantic search, including k-nearest neighbors (kNN) and approximate nearest neighbor (ANN) search, with flexible multi-cloud model management provided for popular NLP models and an open inference API. Elastic provides ELSER, Elastic’s out-of-domain model, and access to reranking models to improve search results. Elasticsearch also seamlessly integrates with key third-party ecosystem products from providers such as Cohere, LangChain, and LlamaIndex. Elasticsearch can be self-managed or deployed with Elastic Cloud.
- Parsing, Chunking, and Vector Embeddings: Elasticsearch excels at parsing and chunking data into manageable segments within a single document for various chunking strategies; preparing it for efficient retrieval and analysis. You can learn more in this blog about chunking via ingest pipelines.
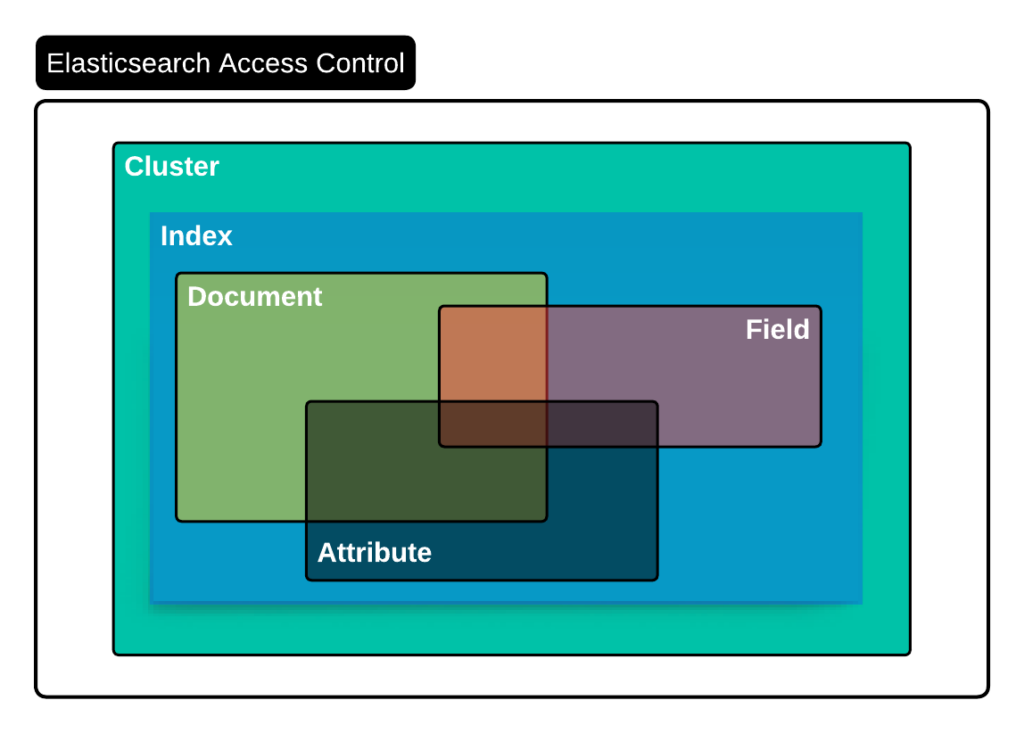
- Secure by default: Elasticsearch provides granular and tiered access control policies to secure the data. Elasticsearch can integrate with industry-standard auth providers in enterprises such as LDAP, SAML, etc. You can read more about Elasticsearch security features in the context of RAG at RBAC and RAG – Best Friends
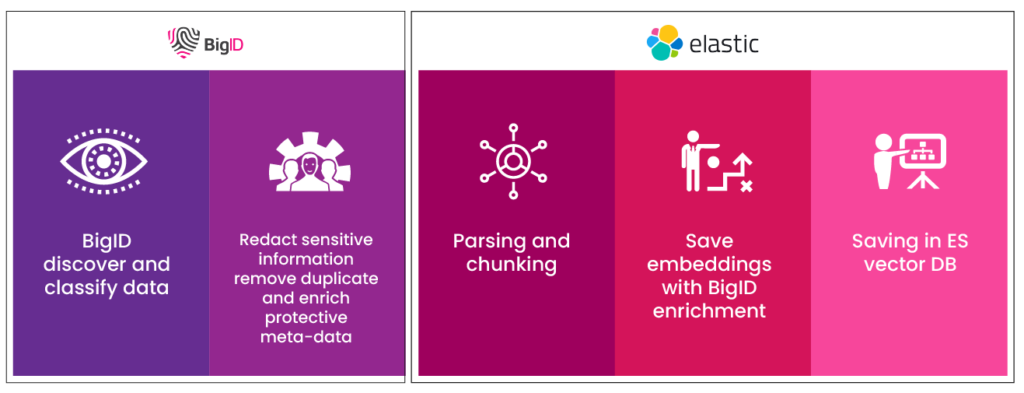
BigID’s Data-Centric, Risk-Aware Security
While VectorDBs themselves offer secure storage, the data they contain can be sensitive, biased, or restricted. This is where BigID’s industry-leading data security and governance capabilities come into play:
- Data Discovery and Classification: Pinpoint sensitive information across various knowledge sources leveraging AI and ML-based discovery and classification capabilities. Identify all types of sensitive data, including PII, PHI, PCI, secrets, IP, and more.
- Sensitive Data Redaction: Redact sensitive information within VectorDBs, mitigating the risk of exposure during LLM training and retrieval.
- Data Access Control & Sensitivity Labels: Facilitate metadata creation on data vectors, specifying authorized users and groups with appropriate access levels. Additionally, completely and accurately apply sensitivity labels (Restricted, Internal Use, Confidential, Public) to data vectors, ensuring users only access authorized information.
- Data Freshness Indicators: Embed metadata within vectors to track data staleness (last updated, accessed, and created). This allows RAG applications to prioritize retrieval of the most up-to-date information.
- Duplicate Detection and Removal: Identify and remove duplicate documents before vectorization, preventing redundant information retrieval and improving overall system efficiency.
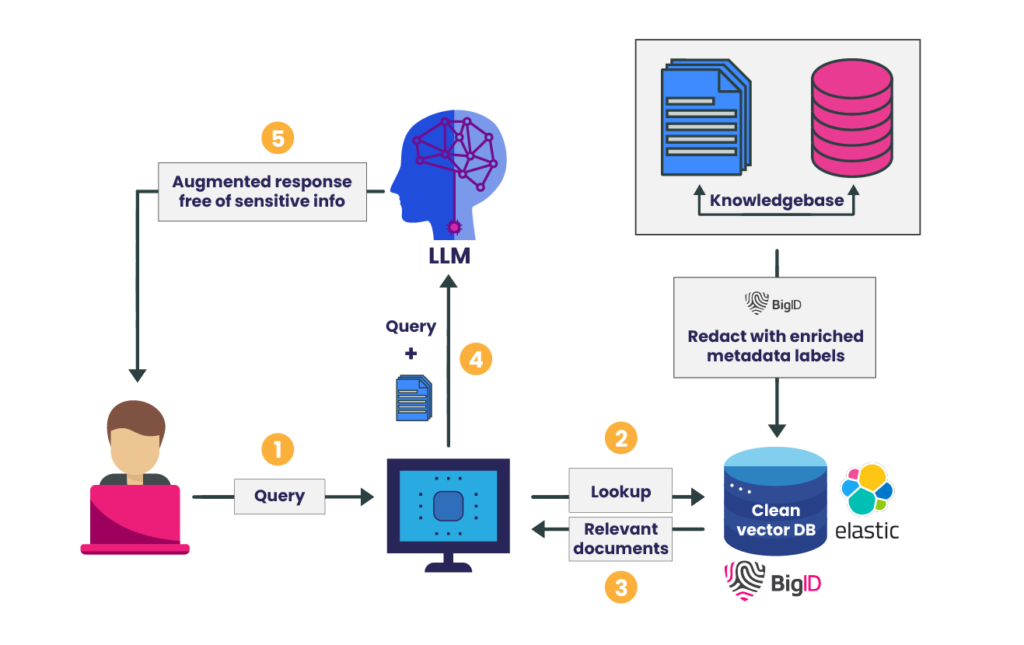
BigID’s data context and insights along with Elastic’s search and analytics expertise unlocks the full potential of secure RAG applications:
- Deploy Secure RAG Applications Faster: Reduce the time it takes to deploy RAG applications into production with confidence.
- Increase User Adoption: Deliver RAG applications cleansed of sensitive data and irrelevant information, fostering greater user adoption and trust.
- Minimize Data Exposure Risk: Mitigate the risks associated with sensitive data linkage within RAG architecture.
- Enhance Data Retrieval and Relevance: RAG applications can retrieve data based on user access permissions and prioritize fresh data, minimizing data leakage risks and delivering the most relevant and valuable outputs to end users.
BigID and Elastic offer a powerful toolkit, minimizing security risks while maximizing the potential of RAG applications. Unlock hidden insights and drive innovation with confidence. Want to learn more? Set up a 1:1 with one of our BigID AI security experts today!
