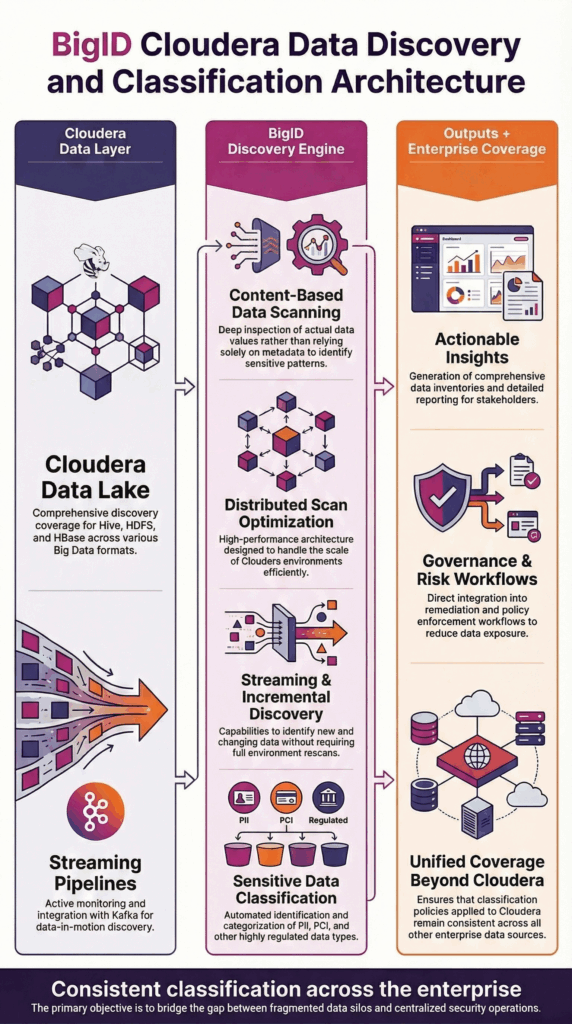
BigID connects securely to Cloudera environments to perform content-based data discovery across Hive, HDFS, HBase, and streaming pipelines. It scans actual data values across structured, semi-structured, and unstructured datasets to accurately identify sensitive and regulated information.
BigID supports distributed processing to align with large-scale Cloudera deployments, enabling scalable discovery across data lake environments while maintaining operational performance.
Discovery results integrate with enterprise classification policies, governance workflows, and reporting frameworks to deliver actionable visibility across the broader data ecosystem.
This architecture ensures precise, enterprise-scale Cloudera data discovery without disrupting production workloads.