

Thanks to great advances and breakthroughs in the area of Natural Language Processing (NLP), we have access to a vast amount of ready to use Named Entity Recognition (NER) classifiers. These classifiers are available in many common languages, and their variety is growing rapidly. There are models that cover language entities relevant to many use cases straight out of the box. However, in many cases, off-the-shelf-functionality is not sufficient to achieve the best performance for a specific use because of incompatibility between the production data and the data that the model was trained on. In these cases, enriching the training data with additional samples significantly improves the accuracy of the model.
In this article we will discuss:
- Why you should consider training your own models
- The use of transfer learning to reduce data collection costs
- Effective and efficient data annotation with machine learning
Why should you still consider training your own NER classifiers?
When we train a machine learning model, we don’t just want it to model the training data. We want the model to have the capability to adapt and react to previously unseen new data, which has been drawn from a similar, but not identical, distribution as the one used to train the model.
For example, when we build a model that aims to recognize full names in free text, we want it to be able to recognize names that don’t even appear in the training dataset. How? By considering not only the name itself – but also its context.
Consider the following sentence: ‘The first time she used her sword, Arya Stark was only a nine years old girl ’. Using the context, a model can predict that Arya Stark is a person’s name even if that specific name does not appear in the training data.
Another example where context plays an important role is being able to distinguish between entity types even if the word itself is the same. Using contextual clues, a model can learn that “Apple” is an organization in one context but it is a fruit in another context.

This consideration of context is why training data should be as representative as possible of the data that we will process in production. A model trained on BBC documents, where sentences in the first person are extremely rare, will likely perform badly on movie transcripts. Similarly, a model trained on literature collections will likely perform badly on financial text.
The cost of training a new classifier
The vast amount of deep learning tools and open source libraries available today, such as SpaCy, enable us to quickly build new NER classifiers. The data collection and annotation for a project like this is by far the most costly and time-consuming part.
A typical project requires several thousand documents to build a representative training corpus – and it usually takes months to collect and annotate all these documents.
A Study on the Importance of and Time Spent on Different Modeling Steps (M. Arthur Munson, Sandia National Laboratories) shows that data collection, organizing, cleaning, and labeling can take about 80% of total time spent on a project.
Transfer Learning
That’s where ready to use NER classifiers come in. These classifiers are already trained on large document datasets, reducing the costs (time and resources) of data collection. The process of taking a trained model and adapting it to your specific data is called transfer learning.
The core idea of transfer learning is to leverage knowledge gained while solving one problem – and apply it to a distinct but related problem. For example, knowledge gained while learning to recognize person names could also be applied (transferred!) to recognize organization names.
In practice, we take a pre-trained model, update the target variable to our needs and train the new model. By doing this we do not start from zero, but build upon the learning already completed by the pre-trained model. Using transfer learning significantly reduces the amount of data needed to be annotated by human labelers typically from several thousands of examples to several hundreds.
Model-Aided Labeling
The problem is that even annotating only hundreds of examples is expensive and resource intensive. Labeling entities in large documents of free text is a difficult task that requires a lot of concentration and is prone to human errors.
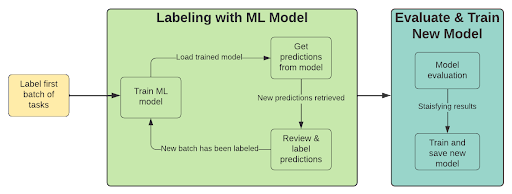
One way to reduce the amount of labeling work is to combine a machine learning model in the annotation process. The approach uses model predictions to pre-annotate new examples, allowing a human to then rapidly review these annotations, confirming or rejecting them as appropriate. This is an iterative process with the following steps:
- Label a batch of examples
- Train a model (using transfer learning)
- Pre-label with trained model
- Review low confidence predictions
- Label a new batch of examples (pick those were model performance is low)
- Repeat from step 2 until you are satisfied with the results
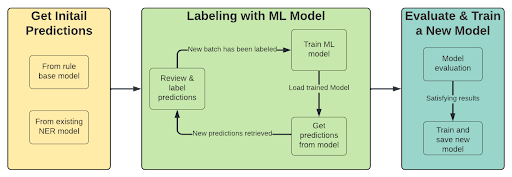
If we already have a NER classifier with the required entities, the initial step of the process changes. The first step is getting predictions from the model (or Regex) in order to use these predictions to annotate documents with low scores.
The process then becomes:
- Pre-label with trained model or Regex
- Review low confidence predictions
- Label a new batch of examples (pick those were model performance is low)
- Train a model (using transfer learning)
- Repeat from step 1 until you are satisfied with the results
Benefits of labeling with model in the loop:
- Eliminate rather than recognize – Labeling free text requires a lot of concentration from the side of the labeler who needs to find specific phrases in possibly long text. This type of task is prone to human errors and takes a lot of time (and requires pre-existing knowledge of the situation). By using pre-annotation, we let the labeler focus more on elimination of incorrectly labeled entities which is a much easier task. This is done by tuning model parameters to produce predictions with high recall.
- Focus on the important tasks – calculating model metrics on the training data allows us to focus on labeling new documents where we see that the model struggles.
- Error analysis – reviewing false positive / negative predictions as part of the annotation process can identify issues such as ambiguity of entity definition in the early stage of the project.
By taking full advantage of both transfer learning and model-aided labeling, we can take advantage of the time and resource (human and computer) saving in labeling and training to bring models for our use case both more quickly and more cheaply.
With BigID, you can customize your own NER classifiers, and even models for other languages to get a deeper and more accurate contextual insight tailored to your specific datasets. Dive in and see for yourself with BigID University’s Data Classification course.