

Können Sie alle Ihre Daten anhand ihrer Sensibilität oder Kritikalität identifizieren und verwalten? Wenn Sie diese Frage nicht eindeutig mit „Ja“ beantworten können, sind Sie nicht allein. Mit dem rasanten Wachstum öffentlicher, privater oder hybrider Cloud-Modelle vermehren sich Daten im gesamten Netzwerk mit unglaublicher Geschwindigkeit. Kein Wunder, dass IT-Teams schon Schwierigkeiten haben, die grundlegenden Daten zu kennen, geschweige denn deren sensiblen Charakter zu verstehen.
Viele Führungskräfte aus den Bereichen Datenschutz, Sicherheit und Governance, mit denen wir heute sprechen, geben an, kein grundlegendes Verständnis für die Sensibilität ihrer Daten in ihrer Umgebung zu haben. Selbst wenn sie sich einen umfassenden Überblick über ihre Daten verschaffen können, fehlt ihnen in der Regel die nötige Kontexttiefe, um proaktive Entscheidungen zu treffen. Leider verlassen sich Unternehmen auf ein Flickwerk veralteter Lösungen, um sich ein fragmentarisches Bild von ihren Daten und deren Klassifizierung zu machen.
IT-Leiter brauchen nicht nur vollständige Transparenz und Kontrolle ihrer Daten, müssen sie ihre Daten in der Kontext der Sensibilität in verschiedenen datenschutz- und sicherheitsrelevanten Bereichen. Diese kontextbezogenen Erkenntnisse ermöglichen umsetzbare Entscheidungen, die das Unternehmen vor bösartigen Bedrohungen schützen können.
Wir freuen uns, die Funktion „Erweiterte Vertraulichkeitsklassifizierung“ vorstellen zu können, mit der Kunden die Vertraulichkeit ihrer Daten einfach, sicher und im großen Maßstab bestimmen können:
- Automatische Erkennung vertraulicher Daten in Ihrer gesamten Umgebung
- Erhalten Sie Einblick in die Sensibilität oder Kritikalität
- Ergreifen Sie Korrekturmaßnahmen, um die Entscheidungsfindung proaktiv voranzutreiben und Cyberrisiken zu mindern.
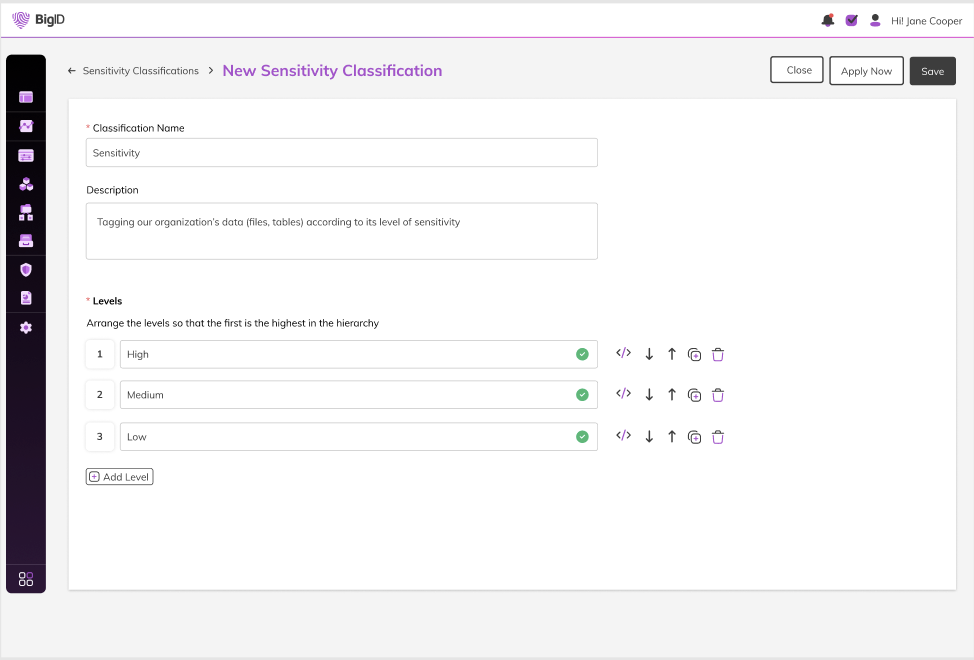
Kennen und verwalten Sie die Sensibilität Ihrer Daten
Nutzung vorhandener KlassifizierungsfunktionenBigID bietet eine Aufschlüsselung von sensiblen und undefinierten Daten. Das Vorhandensein undefinierter Daten bedeutet, dass die bestehende Definition der Sensibilität möglicherweise weiter verfeinert werden muss, um sicherzustellen, dass alle Daten erfasst werden. Mit der erweiterten Sensibilitätsklassifizierung können Unternehmen die Daten nach ihrer Sensibilitätsstufe genauer analysieren.
Diese Stufen werden entweder durch vordefinierte Definitionen bestimmt oder können individuell nach den Interpretationen Ihres Unternehmens definiert werden. Jede Stufe wird durch ein Tag propagiert; jedes Tag wird durch eine Reihe von Regeln und Attributen definiert, die seiner Vertraulichkeitsstufe entsprechen. Beispielsweise könnte ein Vertraulichkeitsklassifizierungstag „Hoch“ für Sozialversicherungsnummern oder Privatadressen definiert werden, während ein Vertraulichkeitsklassifizierungstag „Niedrig“ für etwas Geringeres, wie beispielsweise den Lieblingsfilm eines Kunden, definiert werden könnte.
Erweiterte Regeln zur Vertraulichkeitsklassifizierung lassen sich mit wenigen Klicks implementieren, und die entsprechenden Datenobjekte werden automatisch mit Tags versehen. Noch besser? Unternehmen können diesen Prozess automatisieren, indem sie nach jedem Scan automatisch erweiterte Vertraulichkeits-Tags anwenden.
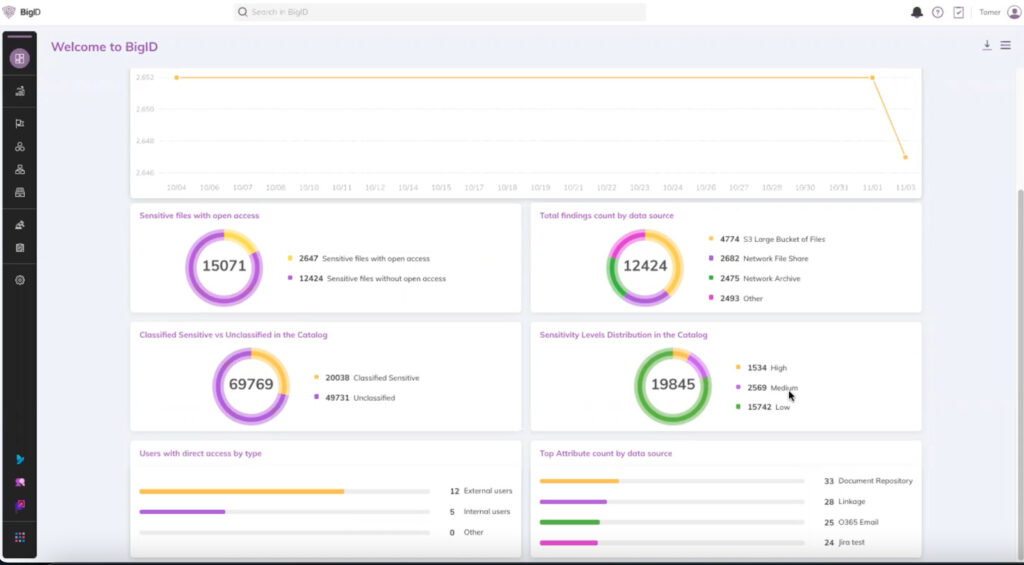
Proaktive Maßnahmen zur Risikominimierung ergreifen
Die erweiterte Sensitivitätsklassifizierung geht über die reine Sichtbarkeit hinaus: Ergreifen Sie Maßnahmen, indem Sie proaktiv Richtlinien für eine bessere Datenkontrolle definieren und anwenden.
- Nutzen Sie Sensibilitätskennzeichnungen und definieren Sie eine Richtlinie dafür, z. B. die Auslösung einer Warnung an die Mitarbeiter, wenn bestimmte Sensibilitätsschwellenwerte überschritten werden.
- Wenn eine bestimmte Vertraulichkeitsstufe erreicht ist, lösen Sie eine bestimmte Aktion aus, z. B. einen API-Aufruf, das Senden einer E-Mail oder das Öffnen eines Jira-Tickets.
- Definieren Sie Workflows, benachrichtigen Sie die richtigen Personen und planen Sie SLAs mithilfe der Data Remediation-App von BigID.
- Integration mit Microsoft Information Protection (MIP) zur Ergänzung und Optimierung Ihrer Datenbeschriftungs-Workflows. Ordnen Sie MIP-Beschriftungen den entsprechenden BigID-Beschriftungen zu und nutzen Sie die Beschriftungsfunktionen von BigID, um Ihre Datenobjekte automatisch mit MIP-Beschriftungen zu versehen.
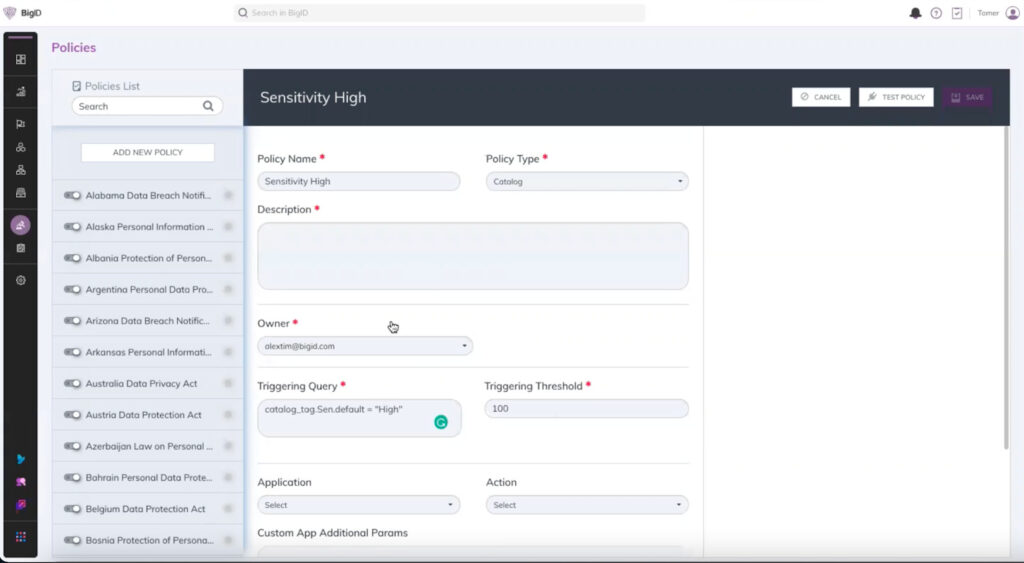
Vorschau der erweiterten Sensitivitätsklassifizierung in Aktion!
BigID unterstützt Unternehmen jeder Größe dabei, ihre Daten zu verwalten, zu schützen und optimal zu nutzen – egal, wo sie sich befinden – vor Ort oder in der Cloud. Verstehen Sie die Vertraulichkeit Ihrer Daten mit der erweiterten Vertraulichkeitsklassifizierung. Holen Sie sich eine 1:1 Demo mit unseren Experten um es heute in Aktion zu sehen.