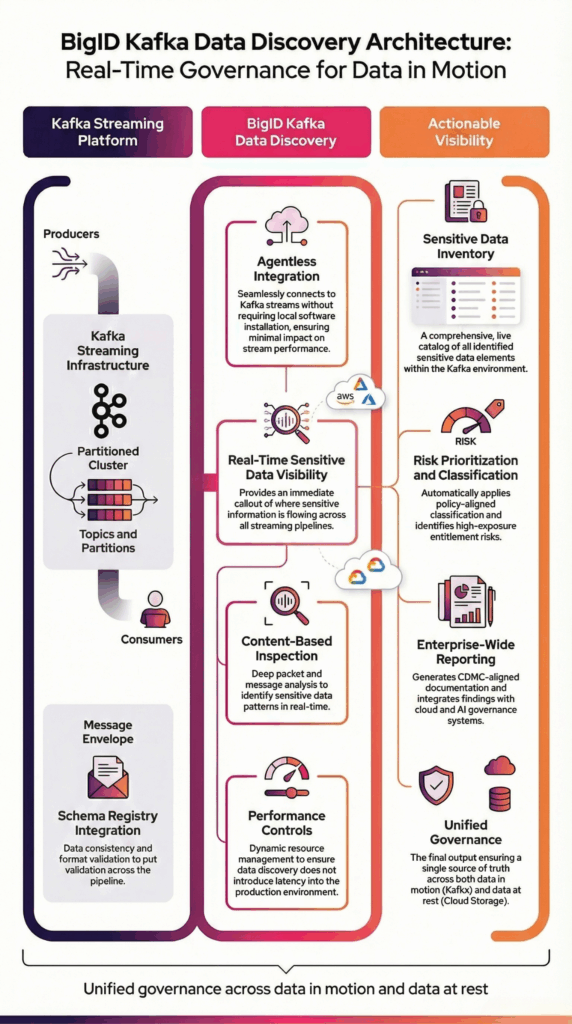
BigID stellt über agentenlose Integration eine sichere Verbindung zu Kafka her, um Streaming-Daten über Themen und Partitionen hinweg zu scannen. Es analysiert die Nutzdaten von Nachrichten auf Inhaltsebene, um sensible und regulierte Informationen in Echtzeit-Datenströmen präzise zu identifizieren.
BigID unterstützt:
- Apache Kafka (Core)
- Konfluentes Kafka
- Avro-Serialisierung mit Schema-Registry-Integration
- Verteilte Partitionen und replizierte Cluster
BigID führt konfigurierbare Stichproben über Abfrageintervalle hinweg durch, um sich an Umgebungen mit hohem Durchsatz anzupassen und gleichzeitig die operative Leistungsfähigkeit zu erhalten.
Die Ergebnisse der Datenanalyse werden in die Klassifizierungsrichtlinien, Governance-Workflows und Berichtssysteme des Unternehmens integriert, um eine einheitliche Transparenz über Streaming- und persistente Datenumgebungen hinweg zu gewährleisten.
Diese Architektur gewährleistet eine skalierbare Erkennung sensibler Kafka-Daten, ohne die Produktionspipelines zu unterbrechen.