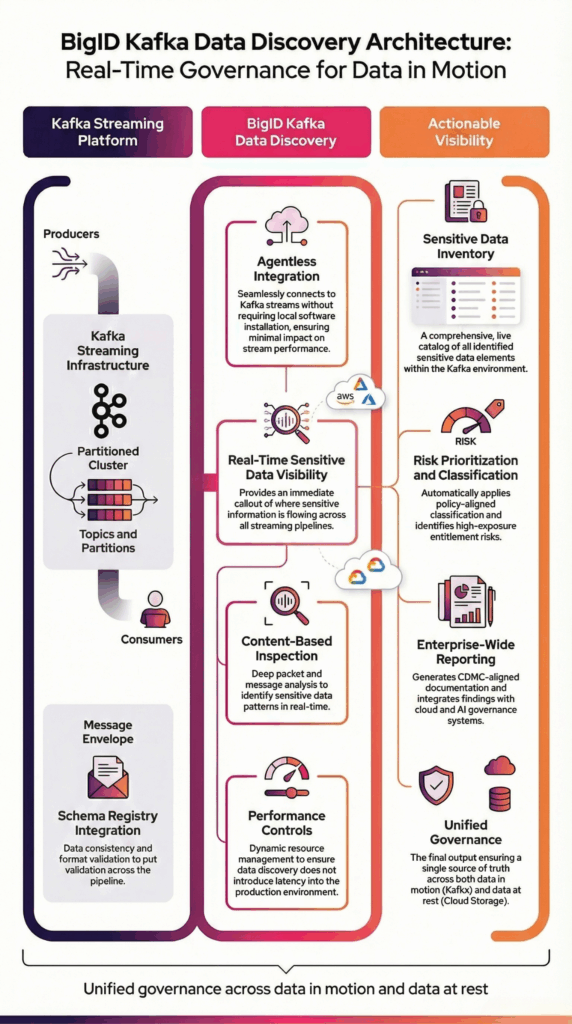
BigID se connecte de manière sécurisée à Kafka via une intégration sans agent pour analyser les données en flux continu à travers les sujets et les partitions. Il analyse le contenu des messages afin d'identifier avec précision les informations sensibles et réglementées au sein des flux de données en temps réel.
BigID prend en charge :
- Apache Kafka (Core)
- Kafka confluent
- Sérialisation Avro avec intégration au registre de schémas
- Partitions distribuées et clusters répliqués
BigID effectue un échantillonnage configurable sur des intervalles d'interrogation afin de s'adapter aux environnements à haut débit tout en préservant les performances opérationnelles.
Les résultats de la découverte s'intègrent aux politiques de classification de l'entreprise, aux flux de travail de gouvernance et aux cadres de reporting afin d'offrir une visibilité unifiée sur les environnements de données en flux continu et persistants.
Cette architecture garantit une découverte évolutive des données sensibles Kafka sans interrompre les pipelines de production.