

Qu'est-ce que Data Fabric ?
Comprendre la gestion et l'intégration des données pour un stockage unifié des données
Tissu de données est une architecture unifiée qui intègre les processus, les données, les analyses et bien plus encore d'une organisation dans un cadre interconnecté. Elle standardise gouvernance des données et les pratiques de sécurité à travers environnements sur site et cloud — y compris le cloud hybride et multicloud.
Les méthodes traditionnelles d'intégration de données reposent sur des connexions point à point et des architectures rigides. Cependant, ce cadre est plus flexible et dynamique. Il permet aux données organisationnelles de circuler librement dans l'ensemble de l'environnement, tout en garantissant sécurité des données.
Contrairement aux pipelines ETL traditionnels, Data Fabric prend en charge les techniques d'intégration de données modernes qui s'adaptent à l'évolution des besoins de l'entreprise et fournissent des données plus efficacement.
L'architecture de la structure de données permet découverte de données Dans un environnement distribué. Cette architecture connecte différentes sources de données, notamment des entrepôts de données cloud, des bases de données sur site et des applications SaaS, pour créer une infrastructure de données centralisée permettant un accès, une intégration et un traitement transparents des données. Cette intégration facilite la combinaison de sources de données, d'applications et d'infrastructures disparates pour la virtualisation des données.
Cela simplifie la gestion des données et accélère leur traitement, permettant ainsi aux organisations d'obtenir des informations et de prendre des décisions éclairées plus rapidement grâce à des données spécifiques. Les ingénieurs et les data scientists peuvent exploiter cette architecture pour rationaliser leurs flux de travail et améliorer leurs capacités d'analyse.
De plus, l'architecture de la Data Fabric peut facilement évoluer pour s'adapter à des volumes de données croissants. Elle réduit les coûts opérationnels et la complexité de l'intégration physique et de la centralisation des données.
Composants de l'architecture Data Fabric
Une structure de données n'est pas un produit unique : c'est une approche architecturale basée sur des fonctionnalités connectées. Bien que chaque implémentation soit légèrement différente, la plupart des structures intègrent quelques éléments communs :
Ingestion et intégration des données
Ce composant rassemble les données provenant du cloud, des systèmes locaux et périphériques en temps réel via le streaming de données et la capture de données modifiées, ou par lots pour des transferts plus importants.
Gestion des métadonnées
Ce processus capture et utilise métadonnées actives Pour comprendre les données existantes, leurs liens avec d'autres ressources et leur gouvernance. Les métadonnées constituent le fondement de l'automatisation et de l'intelligence à l'échelle de l'infrastructure. Elles permettent d'automatiser l'intégration des données et de réduire les tâches manuelles.
Conservation et transformation des données
Les données brutes sont nettoyées, enrichies et préparées afin d'être précises, cohérentes et prêtes à être analysées ou exploitées dans ce composant. Ce processus combine souvent des données provenant de sources diverses pour créer des ensembles de données de meilleure qualité.
Orchestration et livraison
Les pipelines sont coordonnés et les bons flux de données sont livrés de manière fiable aux bons utilisateurs et systèmes, sans transferts manuels ni connexions fragiles.
Accès et consommation
Un accès libre-service et réglementé est fourni aux analystes, aux scientifiques des données et aux applications, afin que les équipes puissent utiliser des données fiables sans créer de nouveaux silos.
Ensemble, ces composants créent une structure unifiée qui s’adapte aux besoins changeants de l’entreprise sans nécessiter que chaque ensemble de données soit déplacé vers un référentiel unique.
Comment fonctionne Data Fabric
Une architecture de données connecte des sources de données distribuées via une couche intelligente basée sur les métadonnées, créant ainsi une vue unifiée des données dans les environnements sur site, cloud et hybrides, sans nécessiter une centralisation complète.
En automatisant la découverte, la gouvernance et l'orchestration, la plateforme peut intégrer des données issues de sources structurées et non structurées et fournir des ensembles de données fiables aux utilisateurs et aux systèmes. Cette approche permet aux équipes d'analyser les données en temps réel tout en garantissant leur cohérence, leur sécurité et leur contrôle face aux modifications.
Pourquoi utiliser une solution Data Fabric ?
Selon IBM, jusqu'à 681 TP3T de données d'entreprise moyennes ne sont pas analysées. De plus, jusqu'à 821 TP3T d'entreprises rencontrent des problèmes d'intégration en raison de données cloisonnées et de différents types de données provenant de différents diverses sourcesSi vous êtes une organisation axée sur les données, ce n’est pas idéal.
« Fabric » fait référence à la couche intégrée de données et aux processus de connexion dans tous les environnements de données, y compris les plateformes hybrides et multicloud.
Grâce à une structure de données cohérente, les entreprises peuvent mieux gérer leurs données. Elles peuvent exploiter les données connectées, les métadonnées et l'analyse de données pour en extraire une valeur maximale en temps réel. Plus important encore, l'amélioration de la qualité des données renforce l'efficacité de l'analyse.
Utiliser une infrastructure de données automatisée est la solution idéale si vous recherchez une solution moderne et efficace pour gérer vos données. Sa visibilité globale vous offre une vue claire et complète de votre environnement de données en temps réel. Cela simplifie le processus de gestion et accélère le traitement des données, vous permettant ainsi de prendre des décisions plus rapides et plus éclairées.
L'utilisation de solutions Data Fabric facilite l'évolutivité et la prise en charge du volume et de la diversité croissants des données générées par les entreprises. Les entreprises gagnent ainsi en productivité, prennent de meilleures décisions et devancent la concurrence. L'utilisation d'une structure de données offre également aux utilisateurs un accès sécurisé et conforme à des données de qualité pour réaliser leurs tâches.
Avantages d'une infrastructure de données
Les environnements de données modernes sont complexes. En combinant l'analyse continue, les technologies automatisées, les modèles d'IA et l'apprentissage automatique dans des environnements de données complexes, la Data Fabric peut aider les entreprises à renforcer la confiance dans leurs données, à prendre de meilleures décisions et à accélérer leur transformation numérique. Voici comment :
Amélioration de l'accessibilité et des informations sur les données
Une infrastructure unifiée permet une meilleure visibilité et compréhension des données. Data Fabric offre à votre organisation une vue unifiée et intégrée de ses actifs de données. Cela permet aux parties prenantes d'accéder aux données, de les analyser et d'agir dessus avec plus d'efficacité. Les décideurs obtiennent des informations pertinentes et exploitables, favorisant ainsi une meilleure prise de décision, l'innovation et un avantage concurrentiel.
Amélioration de l'efficacité opérationnelle et de l'agilité
Data Fabric simplifie l'intégration, la gouvernance et la gestion des données afin de réduire la complexité et l'inefficacité des opérations de données. accès aux données Le contrôle et la gestion rationalisent considérablement les initiatives de gestion des données, libérant ainsi du temps aux équipes de gouvernance. Votre organisation peut ainsi réagir plus rapidement à l'évolution des besoins métier, faire évoluer ses initiatives de données et favoriser l'excellence opérationnelle et l'agilité.
Innovation accélérée et délai de rentabilisation
Une structure de données vous permet de mieux protéger et réduire les coûts de la maintenance et de la gestion des données, notamment dans les environnements multicloud. Votre entreprise peut exploiter pleinement le potentiel de ses données pour stimuler l'innovation et générer de nouvelles opportunités commerciales. Elle démocratise l'accès aux données et favorise une culture d'expérimentation et de collaboration. C'est ainsi que l'architecture de données permet aux équipes d'innover, d'itérer et de créer de la valeur pour les clients plus rapidement et plus efficacement.
Conformité renforcée en matière de confidentialité et de sécurité
Data Fabric intègre des mécanismes robustes de gouvernance, de sécurité et de conformité pour garantir la confidentialité, l'intégrité et la confidentialité des données sensibles. Il vous aide à mettre en œuvre des contrôles d'accès, des techniques de chiffrement et de masquage des données pour protéger les données au repos et en transit. De plus, Data Fabric permet à votre organisation de se conformer aux lois sur la confidentialité des données, telles que GDPR, CCPAet HIPAA en offrant une visibilité sur la lignée des données, leur utilisation et la gestion du consentement.
Data Fabric vs Data Mesh
Le maillage de données décrit un autre processus de gestion des données souvent confondu avec la structure de données, mais aborde différemment la problématique des données distribuées. Alors que la structure de données adopte une approche d'interconnectivité universelle, en tissant une infrastructure continue et unifiée pour la gestion des données, le maillage de données est une architecture centralisée destinée à être utilisée dans des silos de données distribués. Cependant, un maillage de données ne répond pas nécessairement à la question de l'interopérabilité.
En fin de compte, les deux approches rendent les données plus accessibles et plus sécurisées, mais la structure de données seule se concentre sur une architecture holistique et interactive.
Data Fabric vs Data Lake
Data Fabric et Data Lake sont deux approches distinctes de la gestion des données d'entreprise. Bien qu'elles puissent paraître contradictoires, elles peuvent en réalité parfaitement coexister. Un Data Lake est un référentiel centralisé permettant de stocker et d'analyser des données structurées et non structurées. À l'inverse, une Data Fabric est une architecture distribuée qui intègre et partage de manière transparente les données entre plusieurs sources et plateformes.
Les lacs de données sont parfaits pour stocker et traiter de grandes quantités de données. Concrètement, cela signifie qu'ils peuvent servir de source de données principale pour une infrastructure de données. Les infrastructures de données, quant à elles, garantissent l'accessibilité et la disponibilité de ces nouvelles données pour les utilisateurs et les applications. Elles offrent la connectivité et l'agilité nécessaires pour accéder aux données et les analyser en temps réel.
Par exemple, un lac de données pourrait stocker et traiter de grandes quantités de données clients, tandis qu'une structure de données pourrait intégrer ces données à d'autres sources, telles que les médias sociaux, pour fournir une vue complète du comportement des clients.
Ces lacs et fabrics de données facilitent la création et la diffusion de produits de données. En les exploitant, les organisations peuvent tirer davantage de connaissances et optimiser l'efficacité de leurs données en temps réel, tout en garantissant leur accessibilité et leur disponibilité à ceux qui en ont besoin.
Relation entre Data Fabric et l'intégration des données
Une infrastructure de données repose sur une intégration automatisée, pilotée par l'IA, qui s'améliore au fil du temps. Une infrastructure efficace automatise plusieurs styles d'intégration, adapte la gestion des données, rationalise leur distribution au sein de l'entreprise, réduit les coûts de stockage et optimise les performances. L'architecture qui en résulte :
- rend les données difficiles à localiser facilement accessibles dans les environnements multicloud et hybrides
- élimine les silos de données
- élimine les outils multiples et manuels
- pérennise les pratiques de gestion des données, à mesure que de nouvelles sources sont ajoutées
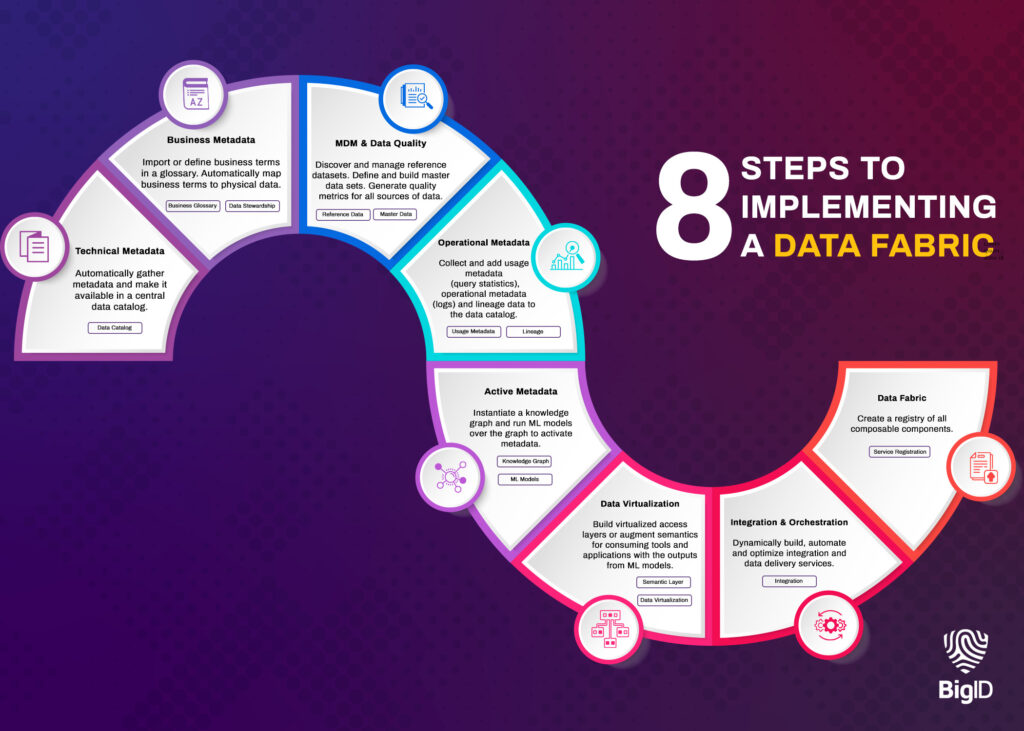
BigID et votre Data Fabric d'entreprise : comment ça marche
BigID présente une approche sémantique basée sur le Machine Learning pour créer une infrastructure de données pour votre organisation. Voici comment la plateforme vous aide à créer une solution d'infrastructure de données fluide pour pérenniser votre transformation numérique et vos pratiques de gestion des données.
Couvrez toutes vos données, partout : Connectez-vous automatiquement à tous les types de données, y compris les données structurées et non structurées, dans des environnements sur site, multicloud et hybrides.
Obtenez une vue unique des métadonnées : Avec un incomparable fondation de découverteBigID peut analyser toutes vos données, partout, pour créer un catalogue de données unifié — et une vue unique de toutes vos métadonnées.
Classer les données en fonction de l'apprentissage profond : BigID est spécialisé dans classification Des méthodes qui vont au-delà de la découverte basée sur des modèles. Classez automatiquement davantage de types de données avec PNL et NER - et Aperçu de l'IA basé sur l'apprentissage profond au sein de l'architecture de gestion des données.
Échanger et partager des données : Permettez la collaboration et le partage de données entre les employés en temps réel.
Ajouter du contexte aux données : Superposez les métadonnées techniques, commerciales et opérationnelles pour voir les attributs et les relations des données.
Exploitez les métadonnées actives pour une meilleure interopérabilité : Grâce aux métadonnées augmentées par ML, obtenez des informations sur vos métadonnées, donnez à votre organisation les moyens d'agir en conséquence et prenez de meilleures décisions commerciales.
Découvrez une démo pour voir BigID en action — et découvrez comment nous pouvons vous aider à créer une structure de données pilotée par ML.
