

Grâce aux grandes avancées et percées dans le domaine de Traitement du langage naturel (NLP), nous avons accès à une grande quantité de ressources prêtes à l'emploi Classificateurs de reconnaissance d'entités nommées (NER)Ces classificateurs sont disponibles dans de nombreux langages courants et leur variété s'accroît rapidement. Certains modèles couvrent des entités linguistiques pertinentes pour de nombreux cas d'utilisation, prêts à l'emploi. Cependant, dans de nombreux cas, les fonctionnalités standard ne suffisent pas à atteindre les meilleures performances pour une utilisation spécifique en raison d'une incompatibilité entre les données de production et celles sur lesquelles le modèle a été entraîné. Dans ce cas, l'enrichissement des données d'entraînement avec des échantillons supplémentaires améliore considérablement la précision du modèle.
Dans cet article, nous discuterons de :
- Pourquoi devriez-vous envisager de former vos propres modèles
- L'utilisation de l'apprentissage par transfert pour réduire les coûts de collecte de données
- Annotation de données efficace et efficiente avec l'apprentissage automatique
Pourquoi devriez-vous toujours envisager de former vos propres classificateurs NER ?
Lors de l'entraînement d'un modèle d'apprentissage automatique, nous ne souhaitons pas seulement qu'il modélise les données d'entraînement. Nous souhaitons que le modèle soit capable de s'adapter et de réagir à de nouvelles données inédites, issues d'une distribution similaire, mais non identique, à celle utilisée pour l'entraînement.
Par exemple, lorsque nous créons un modèle visant à reconnaître des noms complets dans du texte libre, nous souhaitons qu'il soit capable de reconnaître des noms qui n'apparaissent même pas dans l'ensemble de données d'entraînement. Comment ? En prenant en compte non seulement le nom lui-même, mais aussi son contexte.
Considérons la phrase suivante : « La première fois qu'elle a utilisé son épée, Arya Stark n'avait que neuf ans. » En utilisant le contexte, un modèle peut prédire qu'Arya Stark est le nom d'une personne, même si ce nom n'apparaît pas dans les données d'apprentissage.
Un autre exemple où le contexte joue un rôle important est la capacité à distinguer des types d'entités même si le mot lui-même est identique. Grâce à des indices contextuels, un modèle peut apprendre que « Apple » est une organisation dans un contexte, mais un fruit dans un autre.

Cette prise en compte du contexte explique pourquoi les données d'entraînement doivent être aussi représentatives que possible des données que nous traiterons en production. Un modèle entraîné sur des documents de la BBC, où les phrases à la première personne sont extrêmement rares, sera probablement peu performant sur des transcriptions de films. De même, un modèle entraîné sur des recueils de littérature sera probablement peu performant sur des textes financiers.
Le coût de la formation d'un nouveau classificateur
La multitude d'outils d'apprentissage profond et de bibliothèques open source disponibles aujourd'hui, comme SpaCy, nous permet de créer rapidement de nouveaux classificateurs NER. La collecte et l'annotation des données pour un projet comme celui-ci constituent de loin la partie la plus coûteuse et la plus chronophage.
Un projet typique nécessite plusieurs milliers de documents pour constituer un corpus de formation représentatif – et il faut généralement des mois pour collecter et annoter tous ces documents.
Une étude sur l'importance et le temps consacré aux différentes étapes de modélisation (M. Arthur Munson, Sandia National Laboratories) montre que la collecte, l'organisation, le nettoyage et l'étiquetage des données peuvent prendre environ 80% du temps total consacré à un projet.
Apprentissage par transfert
C'est là qu'interviennent les classificateurs NER prêts à l'emploi. Ces classificateurs sont déjà entraînés sur de grands ensembles de données documentaires, réduisant ainsi les coûts (temps et ressources) liés à la collecte de données. Le processus consistant à adapter un modèle entraîné à vos données spécifiques est appelé apprentissage par transfert.
L'idée principale de l'apprentissage par transfert est de tirer parti des connaissances acquises lors de la résolution d'un problème et de les appliquer à un problème distinct, mais connexe. Par exemple, les connaissances acquises en apprenant à reconnaître des noms de personnes pourraient également être appliquées (transférées !) à la reconnaissance des noms d'organisations.
En pratique, nous prenons un modèle pré-entraîné, mettons à jour la variable cible selon nos besoins et entraînons le nouveau modèle. Ce faisant, nous ne partons pas de zéro, mais nous nous appuyons sur l'apprentissage déjà réalisé par le modèle pré-entraîné. L'apprentissage par transfert réduit considérablement la quantité de données à annoter par des étiqueteurs humains, passant généralement de plusieurs milliers à plusieurs centaines d'exemples.
Étiquetage assisté par modèle
Le problème est que même l'annotation de quelques centaines d'exemples est coûteuse et gourmande en ressources. L'étiquetage d'entités dans de volumineux documents de texte libre est une tâche difficile, exigeant beaucoup de concentration et sujette aux erreurs humaines.
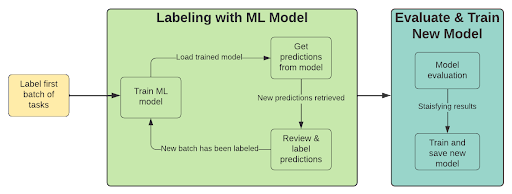
Une façon de réduire le travail d'étiquetage consiste à intégrer un modèle d'apprentissage automatique au processus d'annotation. Cette approche utilise les prédictions du modèle pour pré-annoter les nouveaux exemples, permettant ainsi à un humain de les examiner rapidement et de les confirmer ou de les rejeter si nécessaire. Il s'agit d'un processus itératif comprenant les étapes suivantes :
- Étiqueter un lot d'exemples
- Entraîner un modèle (en utilisant l'apprentissage par transfert)
- Pré-étiquetage avec modèle entraîné
- Examiner les prédictions à faible confiance
- Étiquetez un nouveau lot d’exemples (choisissez ceux dont les performances du modèle sont faibles)
- Répétez à partir de l'étape 2 jusqu'à ce que vous soyez satisfait des résultats
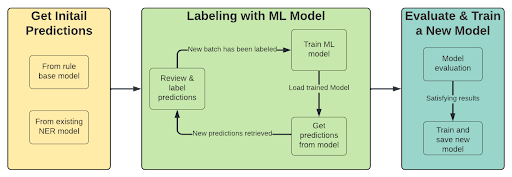
Si nous disposons déjà d'un classificateur NER avec les entités requises, la première étape du processus est différente. La première étape consiste à obtenir des prédictions du modèle (ou de l'expression régulière) afin de les utiliser pour annoter les documents présentant des scores faibles.
Le processus devient alors :
- Pré-étiquetage avec modèle entraîné ou Regex
- Examiner les prédictions à faible confiance
- Étiquetez un nouveau lot d’exemples (choisissez ceux dont les performances du modèle sont faibles)
- Entraîner un modèle (en utilisant l'apprentissage par transfert)
- Répétez à partir de l'étape 1 jusqu'à ce que vous soyez satisfait des résultats
Avantages de l'étiquetage avec modèle dans la boucle :
- Éliminer plutôt que reconnaître L'étiquetage de texte libre exige une concentration importante de la part de l'étiqueteur, qui doit trouver des expressions spécifiques dans un texte potentiellement long. Ce type de tâche est sujet aux erreurs humaines et prend beaucoup de temps (et nécessite une connaissance préalable de la situation). La pré-annotation permet à l'étiqueteur de se concentrer davantage sur l'élimination des entités mal étiquetées, ce qui est une tâche beaucoup plus facile. Cela se fait en ajustant les paramètres du modèle pour produire des prédictions à rappel élevé.
- Concentrez-vous sur les tâches importantes – le calcul des métriques du modèle sur les données d’entraînement nous permet de nous concentrer sur l’étiquetage des nouveaux documents lorsque nous constatons que le modèle rencontre des difficultés.
- Analyse des erreurs – l’examen des fausses prédictions positives/négatives dans le cadre du processus d’annotation peut permettre d’identifier des problèmes tels que l’ambiguïté de la définition de l’entité au début du projet.
En tirant pleinement parti de l'apprentissage par transfert et de l'étiquetage assisté par modèle, nous pouvons profiter des économies de temps et de ressources (humaines et informatiques) réalisées dans l'étiquetage et la formation pour mettre au point des modèles pour notre cas d'utilisation plus rapidement et à moindre coût.
Avec BigID, vous pouvez personnaliser vos propres classificateurs NER, et même des modèles pour d'autres langues, pour obtenir une analyse contextuelle plus approfondie et plus précise, adaptée à vos jeux de données spécifiques. Plongez-vous et découvrez-la par vous-même avec Cours de classification des données de l'Université BigID.