

Cadre DLP
Prévention de la perte de données (DLP) répond aux préoccupations en matière de sécurité des données grâce à des politiques et des règles empêchant la sortie de données sensibles de l'organisation. Ces règles reposent sur les connaissances actuelles concernant les données et leurs métadonnées associées. De nouveaux types de données sont apparus, notamment données cloudLa prévention des pertes de données (DLP) n'est plus aussi efficace qu'auparavant. De plus, la définition de la DLP est devenue plus floue. Heureusement, Gartner a défini un cadre de fonctionnement de la DLP en 5 étapes pour une mise en œuvre réussie de la prévention des pertes de données.

Gartner indique que les solutions DLP ont une portée limitée et qu'il est probable que plusieurs fournisseurs de DLP soient nécessaires pour répondre aux besoins d'une entreprise. Cela peut entraîner des incohérences et des erreurs d'interprétation des politiques. De plus, dans le Guide du marché pour la prévention des pertes de données, Gartner indique que les fournisseurs de DLP s'appuient sur des services de classification des données.
Les problèmes de sécurité des données suivants nécessitent plus que ce que DLP peut offrir à lui seul :
- Découverte améliorée
- Classification
- Contrôle d'accès contextuell
BigID peut grandement améliorer le processus DLP pour ces besoins de données clés.
Pourquoi la DLP seule ne suffit pas
Les préoccupations liées à la DLP trouvent leur origine dans son introduction. À ses débuts, les échanges de données entrants et sortants d'une organisation se limitaient principalement aux e-mails. La DLP se concentrait sur le corps de l'e-mail, en plus des quelques documents de productivité généralement joints. Au fil du temps, le volume, la vitesse, la variété et la véracité des données ont augmenté de manière exponentielle.
BigID peut grandement améliorer le processus DLP pour ces besoins de données clés.
Les individus communiquent par e-mail, Slack, les réseaux sociaux et autres canaux. De plus, presque tous les membres de l'organisation ont accès à de nombreux services SaaS et cloud et transfèrent continuellement des données en conséquence. Ce qui était autrefois une question de création simple règles de correspondance de motifs Le signalement des données sensibles est loin d'être suffisant. En réalité, il est désormais quasiment impossible de créer de telles règles pour des milliers de types de données et des milliards d'éléments. Ce malaise a entraîné une augmentation du nombre de faux positifs identifiés par les outils de prévention des pertes de données (DLP), au point que des données critiques sont bloquées et que leur sortie est ralentie. En revanche, le nombre de faux négatifs est encore plus inquiétant : des données véritablement sensibles ne sont pas correctement identifiées et échappent ainsi aux règles des outils de prévention des pertes de données (DLP).
Alors que la DLP partait initialement du principe de capturer les données sensibles dès leur sortie de l'organisation, BigID adopte une approche différente. Vous ne pouvez créer des règles que pour les données dont vous avez connaissance. BigID estime que vous devez en savoir le plus possible sur vos données, y compris toutes vos données et leur emplacement.
- Structuré
- Semi-structuré
- Non structuré
- Données en vol
- données SaaS
- Données CSP
- Sur site
- Hybride
Si vous disposez d'une cartographie complète de toutes les données, vous pouvez commencer par protéger les données les plus sensibles, et non celles qui sortent de l'organisation à ce moment-là. Classification de sensibilité BigID et les contrôles d'accès rendent les données sensibles inaccessibles dans la plupart des situations où la DLP s'appliquerait. C'est là que BigID peut remplacer les solutions DLP existantes ou les améliorer pour les rendre plus précises et prévisibles.
L'approche de BigID face aux défis DLP
La vaste liste de connecteurs de BigID vers des centaines de sources de données Vous permet d'analyser même les sources de données complexes et peu connues. De plus, BigID dispose de 600 classificateurs de nouvelle génération prêts à l'emploi, exploitant non seulement la correspondance basée sur des modèles, mais aussi Classificateurs ML basés sur le NLP, Analyse de l'IA basée sur l'apprentissage profond, l'identification des documents et la classification brevetée des analyses de fichiers.
À titre d’exemple, la capacité de BigID avec les classificateurs NLP peut identifier certains nombres dans un texte fluide comme l’âge d’une personne et donc probablement sensibles, mais un outil DLP ne serait pas en mesure de le détecter. La découverte et la classification augmentées par ML aboutit à un registre de données robuste et catalogue de métadonnées avec niveaux de sensibilité appliqué aux données. L'accès aux données peut être accordé ou restreint en fonction de la sensibilité des données. Ce niveau de protection est plus robuste que la tentative de capturer des données sensibles alors qu'elles circulent dans les nombreuses technologies de communication et de transfert de données de l'organisation.
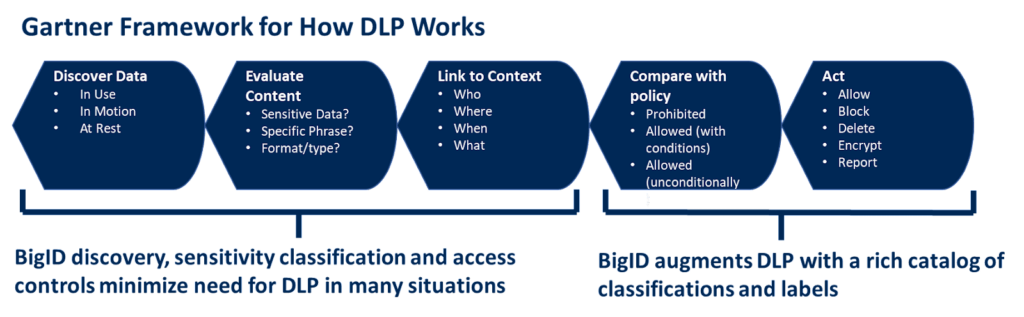
La DLP aura toujours sa place comme niveau de protection supplémentaire, en complément des règles d'accès aux données basées sur les artefacts de données réels. Cependant, BigID peut alléger considérablement la pression sur les outils DLP en fournissant l'un des ensembles d'API les plus complets et les plus ouverts du secteur. Relier le référentiel BigID de métadonnées et de données classifiées, organisées et qualifiées, avec les niveaux de sensibilité correspondants, à la solution DLP pour créer et enrichir les règles réduira considérablement les faux positifs et négatifs, les menaces internes et allégera la pression sur la solution DLP.
Pour en savoir plus sur la façon dont La plateforme de Data Intelligence de BigID peut vous aider à combler le fossé entre vos outils DLP, à mettre en place un Démonstration 1:1 avec nous pour le voir en action.