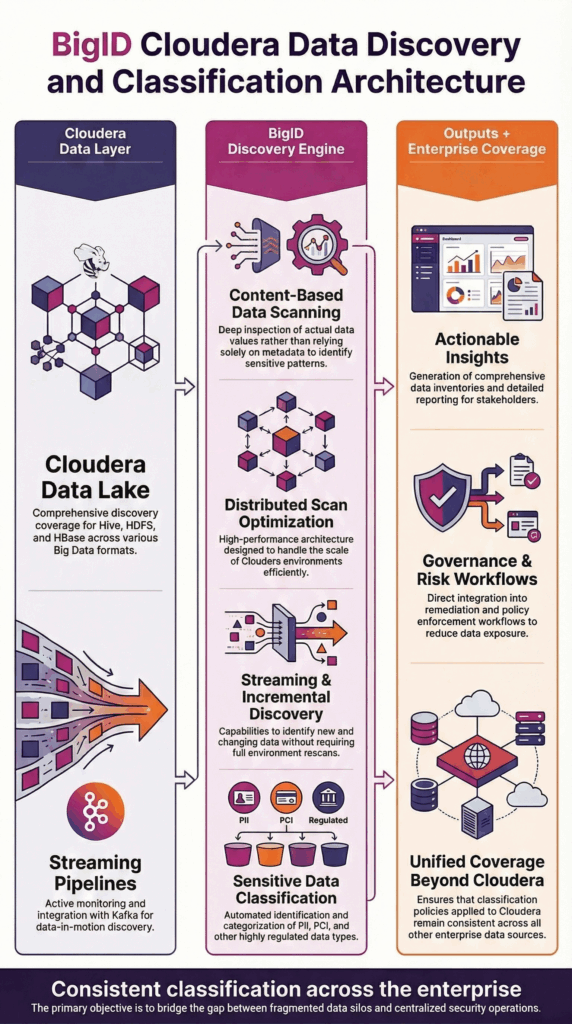
BigID stellt eine sichere Verbindung zu Cloudera-Umgebungen her, um inhaltsbasierte Datenanalyse in Hive, HDFS, HBase und Streaming-Pipelines durchzuführen. Es scannt tatsächliche Datenwerte in strukturierten, semistrukturierten und unstrukturierten Datensätzen, um sensible und regulierte Informationen präzise zu identifizieren.
BigID unterstützt die verteilte Verarbeitung, um mit groß angelegten Cloudera-Bereitstellungen kompatibel zu sein und eine skalierbare Erkennung in Data-Lake-Umgebungen bei gleichzeitiger Aufrechterhaltung der Betriebsleistung zu ermöglichen.
Die Ergebnisse der Datenanalyse werden in die Klassifizierungsrichtlinien, Governance-Workflows und Berichtssysteme des Unternehmens integriert, um eine handlungsrelevante Transparenz im gesamten Datenökosystem zu gewährleisten.
Diese Architektur gewährleistet eine präzise Cloudera-Datenermittlung im Unternehmensmaßstab, ohne die Produktionsabläufe zu beeinträchtigen.