

Was ist Data Fabric?
Datenverwaltung und -integration für einheitliche Datenspeicherung verstehen
Datenstruktur ist eine einheitliche Architektur, die die Prozesse, Daten und Analysen einer Organisation in ein vernetztes Framework integriert. Es standardisiert Datenverwaltung und Sicherheitspraktiken in On-Premise- und Cloud-Umgebungen – einschließlich Hybrid- und Multi-Cloud.
Traditionelle Datenintegrationsmethoden basieren auf Punkt-zu-Punkt-Verbindungen und starren Architekturen. Dieses Framework ist jedoch flexibler und dynamischer. Es ermöglicht den freien Datenfluss innerhalb der gesamten Landschaft und gewährleistet gleichzeitig Datensicherheit.
Im Gegensatz zu herkömmlichen ETL-Pipelines unterstützt Data Fabric moderne Datenintegrationstechniken, die sich an veränderte Geschäftsanforderungen anpassen und Daten effizienter bereitstellen.
Die Data Fabric-Architektur ermöglicht Datenermittlung in einer verteilten Umgebung. Diese Architektur verbindet verschiedene Datenquellen, darunter Cloud-basierte Data Warehouses, lokale Datenbanken und SaaS-Anwendungen, zu einer zentralen Datenstruktur, die nahtlosen Datenzugriff, -integration und -verarbeitung ermöglicht. Diese Integration erleichtert die Kombination unterschiedlicher Datenquellen, Anwendungen und Infrastrukturen für die Datenvirtualisierung.
Dies wiederum vereinfacht das Datenmanagement und beschleunigt die Datenverarbeitung. Dadurch können Unternehmen schneller Erkenntnisse gewinnen und fundierte Entscheidungen anhand spezifischer Daten treffen. Dateningenieure und Datenwissenschaftler können diese Architektur nutzen, um ihre Arbeitsabläufe zu optimieren und die Datenanalyse zu verbessern.
Darüber hinaus lässt sich die Data Fabric-Architektur problemlos skalieren, um steigende Datenmengen zu bewältigen. Sie reduziert die Betriebskosten und die Komplexität der physischen Integration und Zentralisierung von Daten.
Komponenten der Data Fabric-Architektur
Ein Data Fabric ist kein einzelnes Produkt, sondern ein architektonischer Ansatz, der aus vernetzten Funktionen besteht. Obwohl jede Implementierung etwas anders aussieht, enthalten die meisten Fabrics einige gemeinsame Bausteine:
Datenaufnahme und -integration
Diese Komponente führt Daten aus der Cloud, vor Ort und von Edge-Systemen in Echtzeit durch Streaming-Daten und Änderungsdatenerfassung oder im Batch für größere Übertragungen zusammen.
Verwaltung von Metadaten
Dieser Prozess erfasst und nutzt aktive Metadaten um zu verstehen, welche Daten vorhanden sind, wie sie mit anderen Assets zusammenhängen und wie sie verwaltet werden sollten. Metadaten bilden die Grundlage für Automatisierung und Intelligenz im gesamten Fabric. Sie helfen, die Datenintegration zu automatisieren und den manuellen Aufwand zu reduzieren.
Datenkuratierung und -transformation
In dieser Komponente werden Daten aus ihrem Rohzustand bereinigt, angereichert und aufbereitet, um sie präzise, konsistent und für die Analyse oder den operativen Einsatz bereit zu machen. Bei diesem Prozess werden häufig Daten aus verschiedenen Quellen kombiniert, um qualitativ hochwertigere Datensätze zu erstellen.
Orchestrierung und Bereitstellung
Pipelines werden koordiniert und die richtigen Datenflüsse werden zuverlässig an die richtigen Benutzer und Systeme übermittelt, ohne manuelle Übergaben oder instabile Verbindungen.
Zugang und Konsum
Für Analysten, Datenwissenschaftler und Anwendungen wird ein geregelter Self-Service-Zugriff bereitgestellt, sodass Teams vertrauenswürdige Daten verwenden können, ohne neue Silos zu erstellen.
Zusammen bilden diese Komponenten eine einheitliche Struktur, die sich an veränderte Geschäftsanforderungen anpasst, ohne dass jeder Datensatz in ein einzelnes Repository verschoben werden muss.
So funktioniert Data Fabric
Ein Data Fabric verbindet verteilte Datenquellen über eine intelligente, metadatengesteuerte Schicht, die eine einheitliche Sicht auf die Daten in On-Premise-, Cloud- und Hybridumgebungen schafft – ohne dass alles zentralisiert werden muss.
Durch die Automatisierung von Ermittlung, Verwaltung und Orchestrierung kann die Infrastruktur Daten aus strukturierten und unstrukturierten Quellen einbinden und Nutzern und Systemen vertrauenswürdige Datensätze bereitstellen. Dieser Ansatz ermöglicht es Teams, Daten in Echtzeit zu analysieren und gleichzeitig Konsistenz, Sicherheit und Kontrolle bei Datenänderungen zu gewährleisten.
Warum eine Data Fabric-Lösung verwenden?
Laut IBM werden durchschnittlich bis zu 681 TP3T der Geschäftsdaten nicht analysiert. Darüber hinaus haben bis zu 821 TP3T der Unternehmen Integrationsprobleme aufgrund von isolierten Daten und unterschiedlichen Datentypen aus verschiedene Quellen. Wenn Sie eine datengesteuerte Organisation sind, ist dies nicht ideal.
„Fabric“ bezieht sich auf die integrierte Datenschicht und die Verbindung von Prozessen über alle Datenumgebungen hinweg – einschließlich Hybrid- und Multi-Cloud-Plattformen.
Mit einer einheitlichen Datenstruktur können Unternehmen ihre Daten besser verwalten. Sie können vernetzte Daten, Metadaten und Datenanalysen nutzen, um in Echtzeit den maximalen Nutzen aus den Daten zu ziehen. Der wichtigste Aspekt dabei ist, dass die verbesserte Datenqualität die Analyse effektiver macht.
Wenn Sie Ihre Daten modern und effizient verwalten möchten, ist die Nutzung einer automatisierten Datenstruktur die richtige Wahl. Die durchgängige Transparenz bietet Ihnen einen klaren und umfassenden Überblick über Ihre Datenlandschaft in Echtzeit. Dies vereinfacht den Datenverwaltungsprozess und beschleunigt die Datenverarbeitung, sodass Sie schnellere und fundiertere Entscheidungen treffen können.
Der Einsatz von Data Fabric-Lösungen erleichtert die Skalierung, um die ständig wachsende Menge und Vielfalt der von Unternehmen generierten Daten zu bewältigen. So können Unternehmen produktiver werden, bessere Entscheidungen treffen und der Konkurrenz einen Schritt voraus sein. Durch die Verwendung einer Fabric erhalten Benutzer außerdem sicheren und konformen Zugriff auf die richtigen Datenqualitätsanforderungen für ihre Datenaufgaben.
Vorteile einer Dateninfrastruktur
Moderne Datenumgebungen sind komplex. Durch die Verknüpfung kontinuierlicher Analysen, automatisierter Technologien, KI-Modelle und maschinelles Lernen in komplexen Datenumgebungen kann Data Fabric Unternehmen dabei helfen, das Vertrauen in ihre Daten zu stärken, bessere Entscheidungen zu treffen und die digitale Transformation voranzutreiben. So geht's:
Verbesserte Datenzugänglichkeit und Einblicke
Eine einheitliche Infrastruktur ermöglicht bessere Datentransparenz und Einblicke. Data Fabric bietet Ihrem Unternehmen eine einheitliche und integrierte Sicht auf seine Datenbestände. So können Stakeholder effizienter und effektiver auf Daten zugreifen, diese analysieren und nutzen. Entscheidungsträger erhalten zeitnahe und umsetzbare Erkenntnisse, die zu besseren Entscheidungen, Innovationen und Wettbewerbsvorteilen führen.
Verbesserte betriebliche Effizienz und Agilität
Data Fabric vereinfacht die Datenintegration, Governance und Verwaltungsprozesse, um Komplexität und Ineffizienzen bei Datenoperationen zu reduzieren. Verbessert Datenzugriff und Kontrolle rationalisiert Datenmanagement-Initiativen drastisch und gibt den Governance-Teams mehr Zeit. Dadurch kann Ihr Unternehmen schneller auf sich ändernde Geschäftsanforderungen reagieren, Dateninitiativen skalieren und operative Exzellenz und Agilität fördern.
Beschleunigte Innovation und Wertschöpfung
Eine Datenstruktur ermöglicht Ihnen besser schützen und Kosten senken der Datenpflege und -verwaltung – insbesondere in Multi-Cloud-Umgebungen. Ihr Unternehmen kann das volle Potenzial seiner Datenbestände ausschöpfen, um Innovationen voranzutreiben und neue Geschäftsmöglichkeiten zu erschließen. Sie demokratisiert den Datenzugriff und fördert eine Kultur des Experimentierens und der Zusammenarbeit. So ermöglicht die Datenarchitektur Teams, schneller und effektiver zu innovieren, zu iterieren und Kunden Mehrwert zu bieten.
Verbesserte Einhaltung von Datenschutz und Sicherheit
Data Fabric umfasst robuste Governance-, Sicherheits- und Compliance-Mechanismen, um den Datenschutz, die Integrität und die Vertraulichkeit sensibler Daten zu gewährleisten. Es unterstützt Sie bei der Implementierung von Zugriffskontrollen, Verschlüsselung und Datenmaskierungstechniken zum Schutz gespeicherter und übertragener Daten. Darüber hinaus ermöglicht Data Fabric Ihrem Unternehmen die Einhaltung gesetzlicher Datenschutzgesetze wie: GDPR, CCPAund HIPAA indem sie Einblick in die Datenherkunft, -nutzung und das Einwilligungsmanagement bieten.
Data Fabric vs. Data Mesh
Data Mesh beschreibt einen weiteren Datenverwaltungsprozess, der oft mit Data Fabric verwechselt wird, das Problem verteilter Daten jedoch anders angeht. Während Data Fabric einen universellen Interkonnektivitätsansatz verfolgt – also eine kontinuierliche, einheitliche Infrastruktur für das Datenmanagement –, ist Data Mesh eine zentral erstellte Architektur für den Einsatz in verteilten Datensilos. Ein Data Mesh berücksichtigt jedoch nicht unbedingt das Problem der Interoperabilität.
Letztendlich sorgen beide Ansätze für einen besseren Zugriff und mehr Sicherheit der Daten, doch nur Data Fabric konzentriert sich auf eine ganzheitliche, interaktive Architektur.
Data Fabric vs. Data Lake
Data Fabric und Data Lake sind zwei unterschiedliche Ansätze zur Verwaltung von Unternehmensdaten. Obwohl sie scheinbar gegensätzlich erscheinen, können sie durchaus koexistieren. Ein Data Lake ist ein zentrales Repository, in dem strukturierte und unstrukturierte Daten gespeichert und analysiert werden können. Im Gegensatz dazu ist ein Data Fabric eine verteilte Architektur, die Daten nahtlos über mehrere Quellen und Plattformen hinweg integriert und teilt.
Data Lakes eignen sich hervorragend für die Speicherung und Verarbeitung großer Datenmengen. In der Praxis bedeutet dies, dass sie als primäre Datenquelle für ein Data Fabric fungieren können. Data Fabrics tragen wiederum dazu bei, dass diese neuen Daten für Benutzer und Anwendungen zugänglich und verfügbar sind. Sie bieten die notwendige Konnektivität und Agilität, um auf Daten zuzugreifen und sie in Echtzeit zu analysieren.
Beispielsweise könnte ein Data Lake große Mengen an Kundendaten speichern und verarbeiten, während ein Data Fabric diese Daten mit anderen Quellen, wie etwa sozialen Medien, integrieren könnte, um einen vollständigen Überblick über das Kundenverhalten zu bieten.
Diese Data Lakes und Fabrics erleichtern die Erstellung und Bereitstellung von Datenprodukten. Durch ihre Nutzung können Unternehmen ihre Echtzeitdaten besser verstehen und effizienter nutzen und gleichzeitig sicherstellen, dass sie für alle, die sie benötigen, zugänglich und verfügbar sind.
Beziehung zwischen Data Fabric und Datenintegration
Ein Data Fabric basiert auf automatisierter, KI-gesteuerter Integration, die sich mit der Zeit verbessert. Ein effektives Fabric automatisiert mehrere Integrationsstile, skaliert das Datenmanagement, optimiert die Datenbereitstellung im gesamten Unternehmen, reduziert die Speicherkosten und maximiert die Leistung. Die resultierende Architektur:
- macht schwer zu findende Daten in Multi-Cloud- und Hybridumgebungen leicht zugänglich
- eliminiert Datensilos
- macht mehrere manuelle Werkzeuge überflüssig
- macht Datenmanagementpraktiken zukunftssicher, wenn neue Quellen hinzugefügt werden
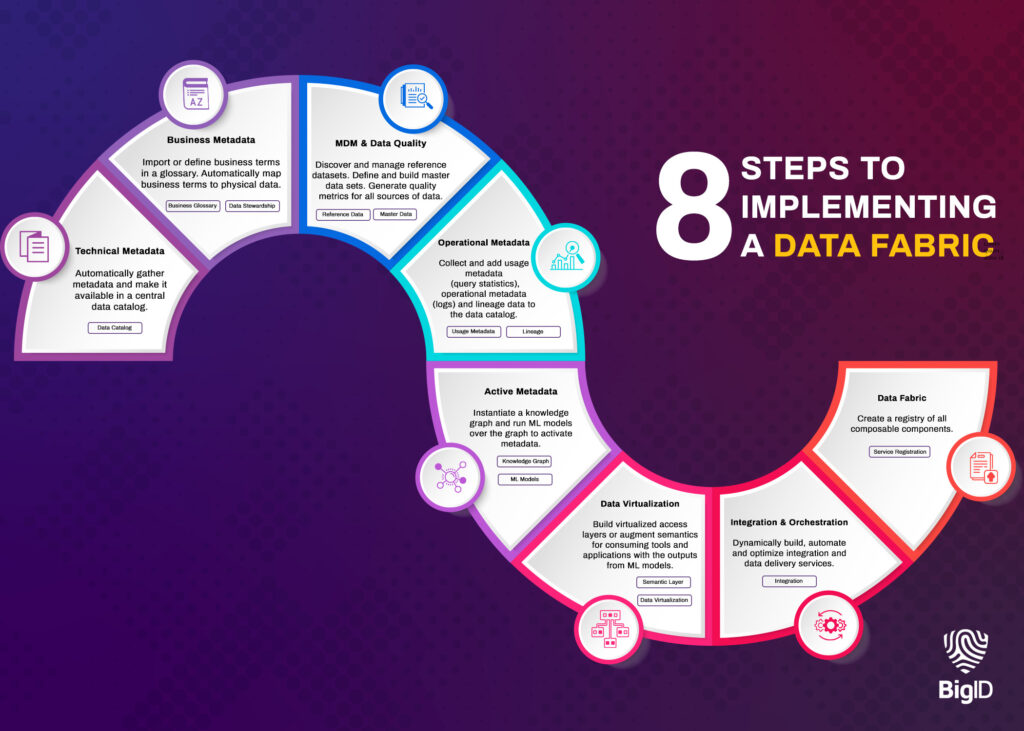
BigID und Ihr Enterprise Data Fabric – So funktioniert es
BigID führt einen ML-gesteuerten, semantischen Ansatz zur Bereitstellung eines Data Fabric für Ihr Unternehmen ein. So unterstützt die Plattform den Aufbau einer nahtlosen Data Fabric-Lösung für zukunftssichere digitale Transformation und Datenmanagementpraktiken in Ihrem Unternehmen.
Schützen Sie alle Ihre Daten – überall: Stellen Sie automatisch eine Verbindung zu allen Datentypen her – einschließlich strukturierter und unstrukturierter Daten – in lokalen, Multi-Cloud- und Hybridumgebungen.
Erhalten Sie eine einheitliche Ansicht der Metadaten: Mit einem unübertroffenen EntdeckungsstiftungBigID kann alle Ihre Daten überall scannen, um einen einheitlichen Datenkatalog und eine einzige Ansicht aller Ihrer Metadaten zu erstellen.
Klassifizieren Sie Daten basierend auf Deep Learning: BigID ist spezialisiert auf Einstufung Methoden, die über die musterbasierte Erkennung hinausgehen. Klassifizieren Sie automatisch mehr Datentypen mit NLP und NER - Und KI-Einblicke basierend auf Deep Learning innerhalb der Datenmanagementarchitektur.
Daten austauschen und teilen: Ermöglichen Sie die Zusammenarbeit und den Datenaustausch zwischen Mitarbeitern in Echtzeit.
Fügen Sie den Daten Kontext hinzu: Überlagern Sie technische, geschäftliche und betriebliche Metadaten, um Datenattribute und -beziehungen anzuzeigen.
Nutzen Sie aktive Metadaten für eine bessere Interoperabilität: Gewinnen Sie mit ML-erweiterten Metadaten Erkenntnisse aus Ihren Metadaten, ermöglichen Sie Ihrem Unternehmen, darauf basierend Maßnahmen zu ergreifen und bessere Geschäftsentscheidungen zu treffen.
Schauen Sie sich eine Demo an, um BigID in Aktion zu sehen – und finden Sie heraus, wie wir Ihnen beim Aufbau einer ML-gesteuerten Datenstruktur helfen können.
