

Dank großer Fortschritte und Durchbrüche im Bereich der Verarbeitung natürlicher Sprache (NLP)haben wir Zugriff auf eine große Menge an gebrauchsfertigen Named Entity Recognition (NER)-KlassifikatorenDiese Klassifikatoren sind in vielen gängigen Sprachen verfügbar, und ihre Vielfalt wächst rasant. Es gibt Modelle, die für viele Anwendungsfälle relevante Spracheinheiten sofort einsatzbereit abdecken. In vielen Fällen reicht die Standardfunktionalität jedoch aufgrund von Inkompatibilitäten zwischen den Produktionsdaten und den Trainingsdaten des Modells nicht aus, um die optimale Leistung für einen bestimmten Anwendungsfall zu erzielen. In diesen Fällen verbessert die Anreicherung der Trainingsdaten mit zusätzlichen Stichproben die Genauigkeit des Modells deutlich.
In diesem Artikel besprechen wir:
- Warum Sie das Trainieren Ihrer eigenen Modelle in Betracht ziehen sollten
- Der Einsatz von Transferlernen zur Reduzierung der Datenerfassungskosten
- Effektive und effiziente Datenannotation mit maschinellem Lernen
Warum sollten Sie dennoch in Erwägung ziehen, Ihre eigenen NER-Klassifikatoren zu trainieren?
Wenn wir ein Machine-Learning-Modell trainieren, wollen wir nicht nur, dass es die Trainingsdaten modelliert. Wir wollen, dass das Modell sich an bisher unbekannte neue Daten anpassen und darauf reagieren kann. Diese stammen aus einer ähnlichen, aber nicht identischen Verteilung wie die, mit der das Modell trainiert wurde.
Wenn wir beispielsweise ein Modell erstellen, das vollständige Namen in freiem Text erkennen soll, soll es auch Namen erkennen können, die im Trainingsdatensatz gar nicht vorkommen. Wie? Indem es nicht nur den Namen selbst, sondern auch seinen Kontext berücksichtigt.
Betrachten Sie den folgenden Satz: „Als Arya Stark ihr Schwert zum ersten Mal benutzte, war sie erst neun Jahre alt.“ Anhand des Kontexts kann ein Modell vorhersagen, dass Arya Stark der Name einer Person ist, auch wenn dieser Name in den Trainingsdaten nicht vorkommt.
Ein weiteres Beispiel, bei dem der Kontext eine wichtige Rolle spielt, ist die Fähigkeit, zwischen Entitätstypen zu unterscheiden, selbst wenn das Wort selbst dasselbe ist. Anhand kontextueller Hinweise kann ein Modell lernen, dass „Apfel“ in einem Kontext eine Organisation, in einem anderen jedoch eine Frucht ist.

Diese Kontextbetrachtung ist der Grund dafür, dass Trainingsdaten möglichst repräsentativ für die in der Produktion verarbeiteten Daten sein sollten. Ein Modell, das mit BBC-Dokumenten trainiert wurde, in denen Sätze in der ersten Person äußerst selten sind, wird bei Filmtranskripten wahrscheinlich schlechte Ergebnisse erzielen. Ebenso wird ein Modell, das mit Literatursammlungen trainiert wurde, bei Finanztexten wahrscheinlich schlechte Ergebnisse erzielen.
Die Kosten für das Training eines neuen Klassifikators
Die große Anzahl an heute verfügbaren Deep-Learning-Tools und Open-Source-Bibliotheken, wie beispielsweise SpaCy, ermöglicht uns die schnelle Entwicklung neuer NER-Klassifikatoren. Die Datenerfassung und -annotation für ein solches Projekt ist der mit Abstand teuerste und zeitaufwändigste Teil.
Für ein typisches Projekt sind mehrere tausend Dokumente erforderlich, um ein repräsentatives Trainingskorpus aufzubauen – und das Sammeln und Kommentieren all dieser Dokumente dauert in der Regel Monate.
Eine Studie über die Bedeutung und den Zeitaufwand verschiedener Modellierungsschritte (M. Arthur Munson, Sandia National Laboratories) zeigt, dass das Sammeln, Organisieren, Bereinigen und Beschriften von Daten etwa 80% der gesamten für ein Projekt aufgewendeten Zeit in Anspruch nehmen kann.
Transferlernen
Hier kommen einsatzbereite NER-Klassifikatoren ins Spiel. Diese Klassifikatoren sind bereits anhand großer Dokumentdatensätze trainiert, was den Aufwand (Zeit und Ressourcen) der Datenerfassung reduziert. Der Prozess, ein trainiertes Modell an Ihre spezifischen Daten anzupassen, wird als Transferlernen bezeichnet.
Die Kernidee des Transferlernens besteht darin, das beim Lösen eines Problems gewonnene Wissen auf ein anderes, aber verwandtes Problem anzuwenden. Beispielsweise könnte das Wissen, das beim Erkennen von Personennamen gewonnen wurde, auch auf das Erkennen von Organisationsnamen angewendet (übertragen!) werden.
In der Praxis nehmen wir ein vortrainiertes Modell, passen die Zielvariable an unsere Bedürfnisse an und trainieren das neue Modell. Dabei beginnen wir nicht bei Null, sondern bauen auf dem bereits erworbenen Lernfortschritt des vortrainierten Modells auf. Durch Transferlernen wird die Datenmenge, die von menschlichen Labelern annotiert werden muss, deutlich reduziert – typischerweise von mehreren Tausend auf mehrere Hundert Beispiele.
Modellgestützte Beschriftung
Das Problem besteht darin, dass selbst die Annotation von nur Hunderten von Beispielen teuer und ressourcenintensiv ist. Die Beschriftung von Entitäten in großen Dokumenten mit freiem Text ist eine schwierige Aufgabe, die viel Konzentration erfordert und anfällig für menschliche Fehler ist.
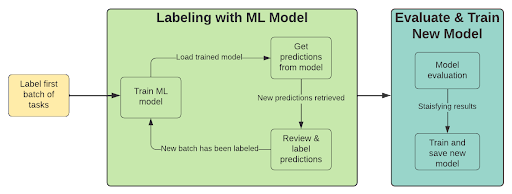
Eine Möglichkeit, den Beschriftungsaufwand zu reduzieren, besteht darin, ein Machine-Learning-Modell in den Annotationsprozess zu integrieren. Dieser Ansatz nutzt Modellvorhersagen, um neue Beispiele vorab zu annotieren. Ein Mensch kann diese Annotationen dann schnell überprüfen und gegebenenfalls bestätigen oder ablehnen. Dies ist ein iterativer Prozess mit den folgenden Schritten:
- Beschriften Sie eine Reihe von Beispielen
- Trainieren Sie ein Modell (mithilfe von Transferlernen)
- Vorbeschriften mit trainiertem Modell
- Überprüfen Sie Vorhersagen mit geringer Zuverlässigkeit
- Beschriften Sie eine neue Gruppe von Beispielen (wählen Sie diejenigen aus, bei denen die Modellleistung niedrig ist).
- Wiederholen Sie den Vorgang ab Schritt 2, bis Sie mit den Ergebnissen zufrieden sind
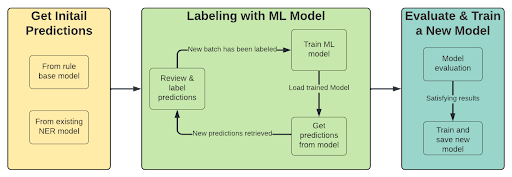
Wenn wir bereits einen NER-Klassifikator mit den erforderlichen Entitäten haben, ändert sich der erste Schritt des Prozesses. Der erste Schritt besteht darin, Vorhersagen vom Modell (oder Regex) abzurufen, um diese Vorhersagen zum Annotieren von Dokumenten mit niedrigen Punktzahlen zu verwenden.
Der Prozess wird dann:
- Vorbeschriften mit trainiertem Modell oder Regex
- Überprüfen Sie Vorhersagen mit geringer Zuverlässigkeit
- Beschriften Sie eine neue Gruppe von Beispielen (wählen Sie diejenigen aus, bei denen die Modellleistung niedrig ist).
- Trainieren Sie ein Modell (mithilfe von Transferlernen)
- Wiederholen Sie den Vorgang ab Schritt 1, bis Sie mit den Ergebnissen zufrieden sind
Vorteile der Beschriftung mit Model in the Loop:
- Eliminieren statt erkennen Das Beschriften von freiem Text erfordert hohe Konzentration des Beschrifters, der bestimmte Phrasen in möglicherweise langen Texten finden muss. Diese Art von Aufgabe ist anfällig für menschliche Fehler und zeitaufwändig (und erfordert Vorkenntnisse). Durch die Verwendung von Vorannotationen können wir den Beschrifter stärker auf die Eliminierung falsch beschrifteter Entitäten konzentrieren, was eine deutlich einfachere Aufgabe darstellt. Dies geschieht durch die Optimierung der Modellparameter, um Vorhersagen mit hoher Trefferquote zu erstellen.
- Konzentrieren Sie sich auf die wichtigen Aufgaben – Durch die Berechnung der Modellmetriken auf Grundlage der Trainingsdaten können wir uns auf die Kennzeichnung neuer Dokumente konzentrieren, bei denen das Modell Probleme hat.
- Fehleranalyse – Durch die Überprüfung falsch positiver/negativer Vorhersagen im Rahmen des Annotationsprozesses können Probleme wie Mehrdeutigkeiten bei der Entitätsdefinition bereits in der frühen Phase des Projekts identifiziert werden.
Indem wir sowohl die Vorteile des Transferlernens als auch der modellgestützten Kennzeichnung voll ausschöpfen, können wir die Zeit- und Ressourcenersparnis (Menschen und Computer) bei der Kennzeichnung und Schulung nutzen, um Modelle für unseren Anwendungsfall schneller und kostengünstiger zu entwickeln.
Mit BigID können Sie Ihre eigenen NER-Klassifikatoren anpassenund sogar Modelle für andere Sprachen, um tiefere und genauere kontextbezogene Einblicke zu erhalten, die auf Ihre spezifischen Datensätze zugeschnitten sind. Tauchen Sie ein und überzeugen Sie sich selbst mit Kurs zur Datenklassifizierung der BigID University.