Découverte et classification de données par l'IA
Identifiez et cataloguez les données sensibles, réglementées et critiques qui alimentent vos modèles d'IA - avant qu'elles ne deviennent une responsabilité.

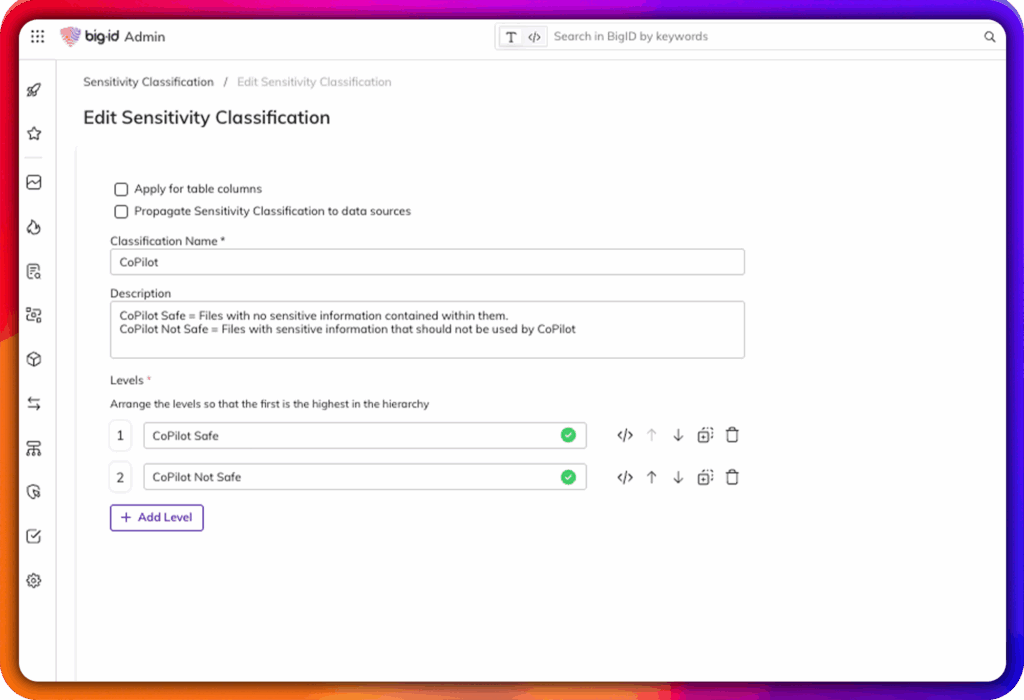
Identifier et supprimer les données personnelles, réglementées ou toxiques des pipelines de formation
Enrichir les ensembles de formation avec des données propres, conformes et bien étiquetées
Garantir l'exactitude, l'exhaustivité et l'intégrité des données afin de réduire les biais et les dérives du modèle.
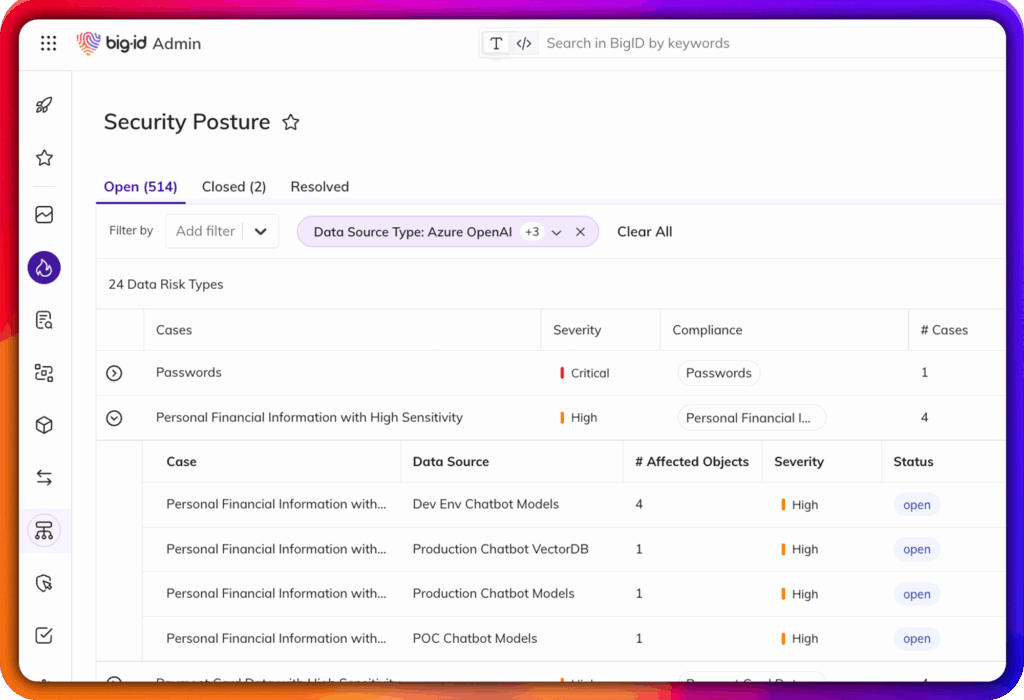
Découvrir l'utilisation de l'IA dans l'ombre, les copilotes non agréés et l'accès non autorisé aux données
Cartographier les flux de données entrant et sortant des systèmes d'IA - y compris les outils tiers
Restreindre l'utilisation de données sensibles ou à haut risque dans les modèles génératifs ou prédictifs
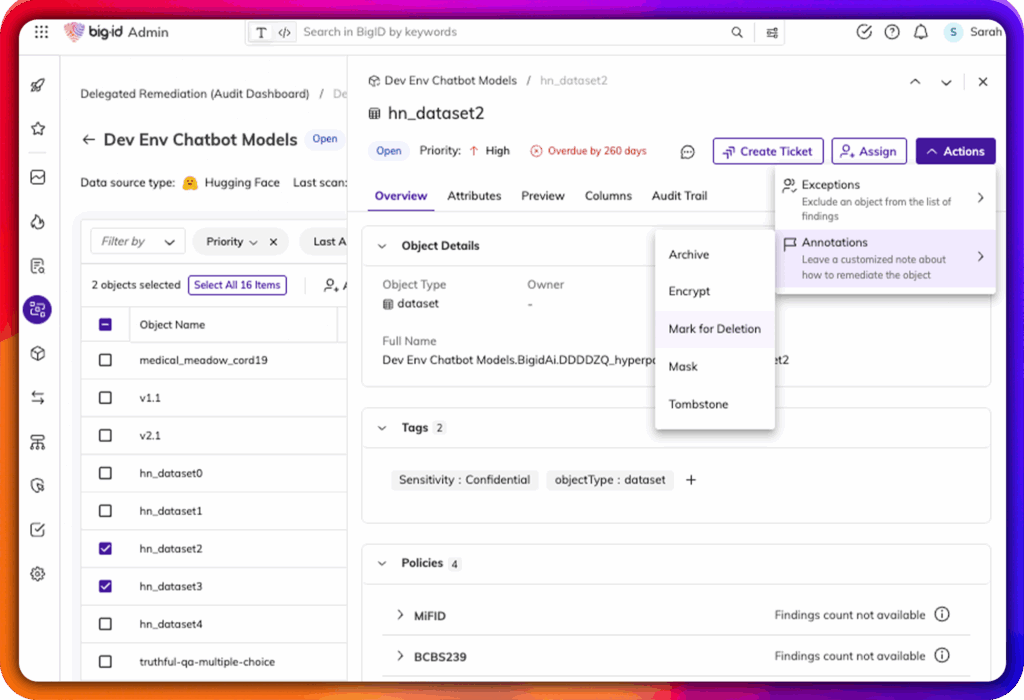
Mettre en évidence les risques d'IA liés à la confidentialité des données, aux violations des politiques et aux mauvaises configurations d'accès.
Automatiser l'application des contrôles de gouvernance de l'IA dans les cycles de vie des données et des modèles
Remédier au risque à la source - du recyclage des modèles à la révocation de l'accès
Identifiez et cataloguez les données sensibles, réglementées et critiques qui alimentent vos modèles d'IA - avant qu'elles ne deviennent une responsabilité.
Veillez à ce que votre IA repose sur des données fiables, conformes et de haute qualité, exemptes de biais, de secrets, d'informations réglementées et d'intrants toxiques.
Supprimez, mettez en quarantaine ou déplacez les données inutiles et surexposées - réduisant ainsi l'empreinte de risque dont votre IA peut hériter.
Découvrez automatiquement où les données de formation, les copilotes, les chatbots ou les services GenAI introduisent des risques en matière de confidentialité, de sécurité ou de conformité - et corrigez les problèmes rapidement.
Trouvez et sécurisez les données sensibles avant qu'elles ne soient accidentellement remontées à la surface par les copilotes et les assistants IA - en vous protégeant contre les fuites, les hallucinations et les divulgations non autorisées.
Restez en phase avec la loi européenne sur l'IA, les réglementations émergentes en matière d'IA, le GDPR, le CPRA et les politiques de gouvernance internes grâce à une visibilité et des alertes en temps réel.
Combler le fossé entre la sécurité des données et Gouvernance de l'IA avec un plate-forme unique conçu pour gérer les deux de manière transparente.
Découvrez, conservez et protégez les données qui sous-tendent votre IA, avec BigID.



