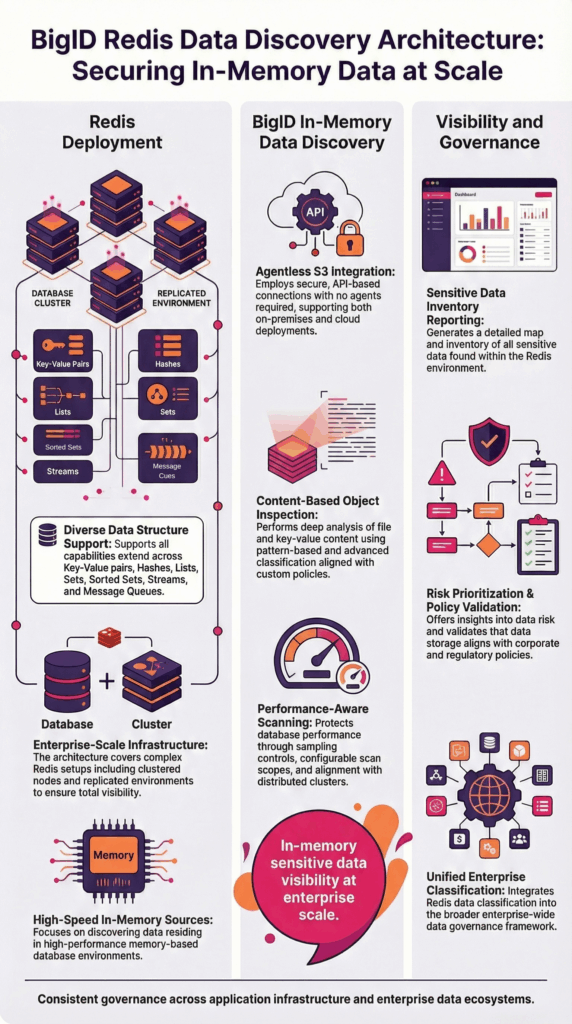
BigID se connecte de manière sécurisée à Redis via une intégration sans agent pour analyser les structures clé-valeur et les types de données pris en charge. Il analyse les valeurs des données stockées en mémoire afin d'identifier les informations personnelles, réglementées et confidentielles.
BigID prend en charge la découverte à travers :
- paires clé-valeur Redis
- Tables de hachage, listes, ensembles et ensembles triés
- Flux et files d'attente de messages
- Environnements Redis clusterisés et répliqués
- Services Redis hébergés dans le cloud et déploiements sur site
Les résultats de l'analyse s'intègrent aux politiques de classification de l'entreprise, aux flux de travail de gouvernance et aux initiatives de visibilité des risques.
Cette architecture garantit que les données Redis ne constituent pas un angle mort dans votre stratégie de sécurité des données.