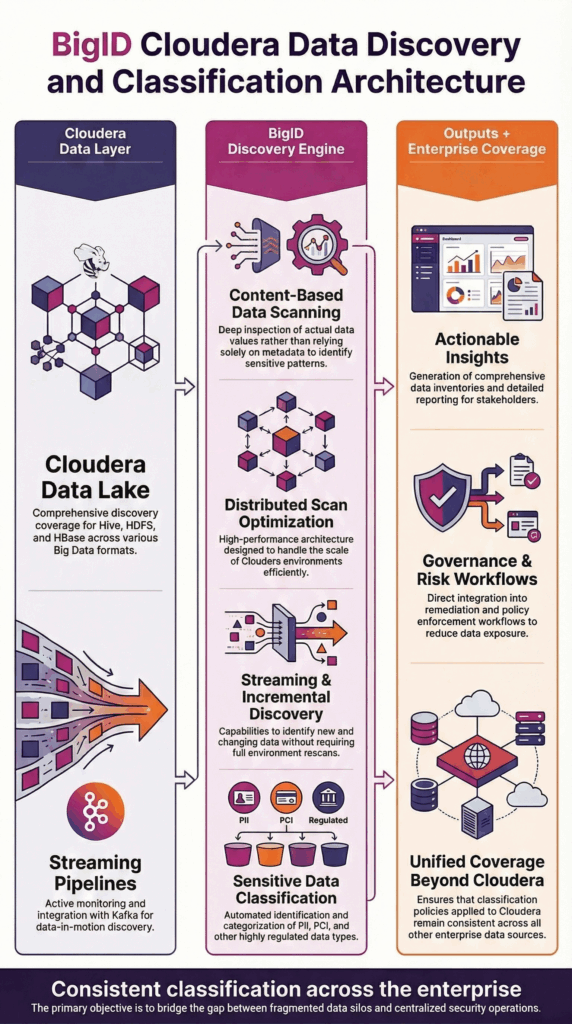
BigID se connecte de manière sécurisée aux environnements Cloudera pour effectuer une exploration de données basée sur le contenu dans Hive, HDFS, HBase et les pipelines de streaming. Il analyse les valeurs des données dans les ensembles de données structurés, semi-structurés et non structurés afin d'identifier avec précision les informations sensibles et réglementées.
BigID prend en charge le traitement distribué pour s'aligner sur les déploiements Cloudera à grande échelle, permettant une découverte évolutive dans les environnements de lac de données tout en maintenant les performances opérationnelles.
Les résultats de la découverte s'intègrent aux politiques de classification de l'entreprise, aux flux de travail de gouvernance et aux cadres de reporting pour offrir une visibilité exploitable sur l'ensemble de l'écosystème de données.
Cette architecture garantit une découverte précise des données Cloudera à l'échelle de l'entreprise sans perturber les charges de travail de production.