

Le AI L'ère a permis de débloquer de puissantes innovations et de créer de nouvelles angles morts de la vie privée. Alors que les modèles ingèrent des volumes massifs de données et s'intègrent dans les interactions quotidiennes avec les clients, les organisations sont confrontées à un défi urgent : empêcher l'exposition des données personnelles, mémorisées ou utilisées à mauvais escient par les systèmes d'IA. Les responsables de la confidentialité, du droit et des données sont désormais tenus de protéger les données sensibles au sein de pipelines d'IA dynamiques et complexes, sans entraver l'innovation.
Le problème : les risques liés à la confidentialité ont dépassé les contrôles traditionnels
Les programmes traditionnels de protection de la vie privée ont été conçus pour des environnements statiques : bases de données structurées, flux de données connus et accès prévisible. Mais les systèmes d'IA ne suivent pas ces règles. Ils consomment des types de données variés, manquent souvent de traçabilité et peuvent révéler involontairement des informations sensibles par inférence.
Les principaux domaines de risque comprennent :
- Formation sur des ensembles de données sans consentement ni classification appropriés
- Fuites involontaires de modèles génératifs PII dans les sorties
- IA de l'ombre et une expérimentation décentralisée introduisant des angles morts
- Pression réglementaire mondiale croissante (Loi européenne sur l'IA, CPRA, Directives RGPD sur l'IA)
Ce qui a changé : Les modèles d’IA ne sont plus seulement des logiciels : ce sont des systèmes basés sur les données qui nécessitent une gouvernance et une surveillance de la confidentialité continues.
Un cadre stratégique pour la confidentialité des données de l'IA
Pour créer des systèmes d'IA fiables et conformes, les programmes de confidentialité doivent évoluer. Voici un cadre général pour guider cette évolution :
1. Inventaire de l'IA dans toute l'entreprise
- Identifier où l'IA est développée, déployée ou expérimentée
- Ensembles de données de catalogue utilisés pour la formation, le réglage fin et l'inférence
2. Intégrer les contrôles de confidentialité dans le cycle de vie de l'IA
- Traitez l’IA comme un fournisseur tiers ou une initiative à haut risque
- Introduire très tôt des évaluations des risques liés à la confidentialité pour les ensembles de données et les modèles
3. Classer et surveiller les données liées à l'IA
- Utilisez des outils automatisés pour étiqueter et signaler les PII, PHI et autres données réglementées
- Surveillez en permanence les dérives de données, l'exposition ou les violations de politiques
4. Établir et appliquer des contrôles de données
- Définir les règles d'utilisation, de minimisation, de conservation et de résidence
- Appliquer une gouvernance basée sur des politiques à travers les phases de formation et d'inférence
5. Construire un alignement interfonctionnel
- Créer une responsabilité partagée entre la science des données, le juridique, la sécurité et la confidentialité
- Former les équipes aux risques liés à la confidentialité de l'IA et aux procédures opérationnelles standard
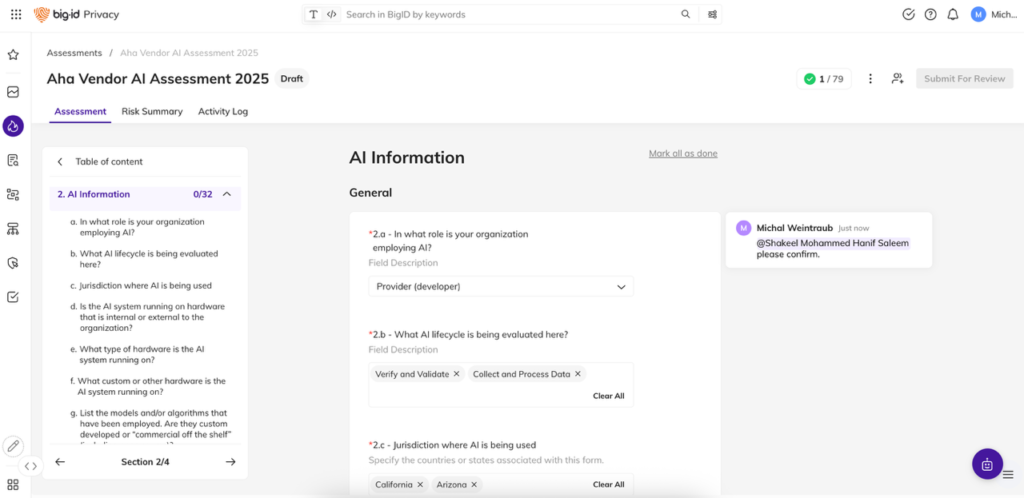
BigID permet aux équipes chargées de la confidentialité, des affaires juridiques et de la sécurité d'opérationnaliser la confidentialité de l'IA à grande échelle.
Si une stratégie adaptée définit la vision, sa mise en œuvre à grande échelle nécessite une plateforme adaptée. BigID aide les organisations à opérationnaliser la confidentialité dans leurs pipelines d'IA, rendant la gouvernance applicable, détectable et vérifiable.
BigID vous aide à :
- Découvrir les données sensibles dans les pipelines d’IA : Analysez automatiquement les données structurées et non structurées utilisées pour la formation, le réglage et l'inférence, y compris les fichiers, le texte, les journaux et les API.
- Classer les données personnelles et réglementées avec précision : Identifiez les PII, PHI, les informations financières et d'autres attributs sensibles grâce à des modèles de classification alimentés par l'IA formés pour des résultats réels en matière de confidentialité.
- Appliquer les politiques de minimisation et de conservation des données : Définissez et automatisez les contrôles afin que seules les bonnes données soient utilisées et conservées uniquement aussi longtemps que nécessaire.
- Gouverner l’IA fantôme et les modèles non autorisés : Identifiez les activités d’IA non autorisées, les utilisations abusives des données et les angles morts de risque avant qu’ils n’entraînent des violations de conformité ou des dommages à la marque.
- Activer la confidentialité dès la conception dans toutes les équipes : Offrez aux équipes juridiques et de confidentialité une visibilité continue sur l'endroit où les données sont utilisées, la manière dont elles sont régies et les politiques en place sans ralentir l'innovation.
Le résultat : Vous réduisez l’exposition, activez l’IA conforme à grande échelle et renforcez la confiance des consommateurs en protégeant les données personnelles dès le départ.
La confidentialité ne peut pas être une réflexion après coup dans l’IA : BigID en fait un avantage intégré.
Réserver une démonstration pour découvrir comment BigID contribue à protéger les données personnelles dans vos systèmes d'IA et permet une innovation conforme et fiable à grande échelle.
