

AI ist nur so vertrauenswürdig wie die Daten, auf denen es basiert. In den meisten Organisationen gibt es jedoch keine klare Regelung, welche Daten in der generativen KI verwendet werden sollen – und welche nicht. Copilotenoder große Sprachmodelle (LLMs). Vertrauliche Dateien werden in Eingabeaufforderungen einbezogen. Proprietäre Inhalte werden offengelegt. Richtlinienverstöße passieren, bevor die Teams überhaupt wissen, dass sie nachsehen müssen.
BigIDs neue Datenbeschriftung für KI ändert das.
Mit dieser Einführung können Sicherheits- und Governance-Teams Daten endlich basierend auf ihrer Verwendung in der KI klassifizieren, kennzeichnen und kontrollieren. Das bedeutet weniger Überraschungen, eine stärkere Richtliniendurchsetzung und mehr Vertrauen in die KI – bevor überhaupt Daten in die Pipeline gelangen.
Warum es wichtig ist
Ohne nutzungsbasierte Kennzeichnung behandeln KI-Tools alle Daten gleich. Und das ist ein Problem.
Manche Daten können problemlos für Schulungen oder Eingabeaufforderungen verwendet werden. Andere wiederum nicht. Solange Teams jedoch nicht kennzeichnen können, was „KI-genehmigt“, „eingeschränkt“ und „verboten“ ist, gibt es keine skalierbare Möglichkeit, KI-Nutzungsrichtlinien durchzusetzen – oder kostspielige Fehler zu vermeiden.
BigIDs Data Labeling für KI löst dieses Problem mit intelligenter, automatisierter Kennzeichnung, die direkt in die Plattform integriert ist.
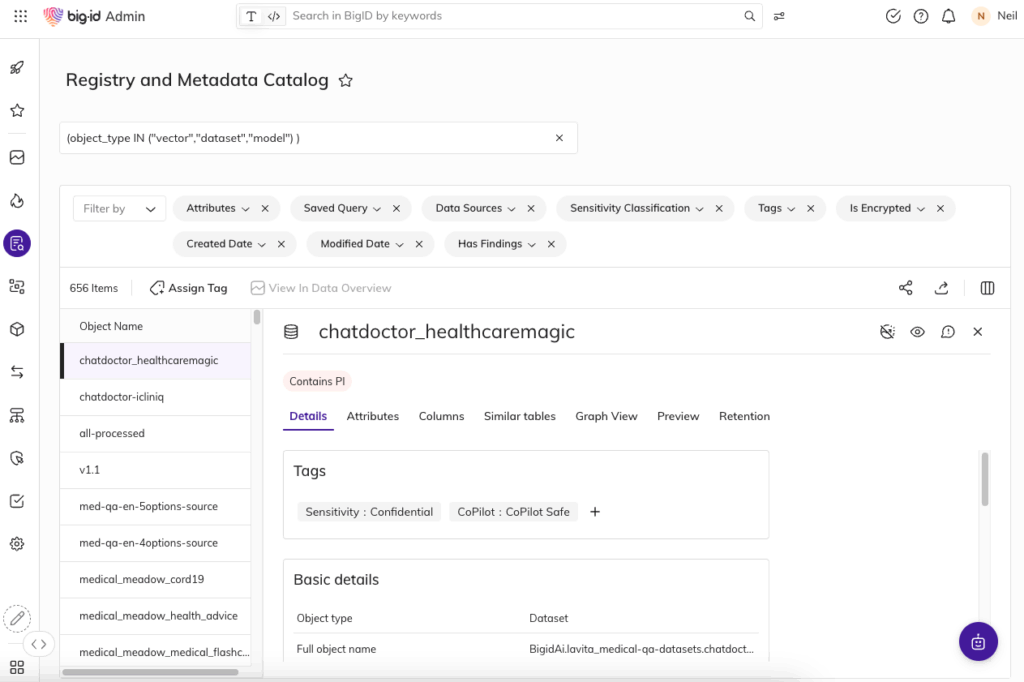
Was es bewirkt
Mit BigIDs Datenbeschriftung für KI können Teams:
- Klassifizieren Sie Daten nach KI-Eignung: Kennzeichnen Sie Daten automatisch danach, ob sie für die Verwendung durch GenAI zulässig sind, mit integrierten Optionen wie „sicher“, „eingeschränkt“ oder „verboten“.
- Passen Sie die Etiketten an Ihre Richtlinien an: Definieren Sie Ihre eigenen Regeln und Risikoschwellenwerte, um interne Governance, gesetzliche Anforderungen oder bewährte Verfahren der Branche zu berücksichtigen.
- Wenden Sie Beschriftungen auf alle Datentypen an: Von strukturierten Systemen über SaaS-Dateien bis hin zu Inhalten für die Zusammenarbeit – die Kennzeichnung funktioniert im gesamten Unternehmen.
- Handeln Sie gemäß den Etiketten: Verwenden Sie die Richtlinien-Engine von BigID, um den Zugriff einzuschränken, Warnungen auszulösen oder die nachgelagerte Verwendung zu blockieren, bevor Daten in Eingabeaufforderungen, Modelle oder Trainingssätze gelangen.
Anwendungsfälle aus der Praxis
- Verhindern Sie Datenlecks an Copiloten: Kennzeichnen Sie vertrauliche Inhalte in SharePoint oder Google Drive als „verboten“ und blockieren Sie automatisch den Zugriff von KI-Plugins darauf.
- Optimieren Sie die GenAI-Bereitschaft: Geben Sie Datenwissenschaftlern einen kuratierten, beschrifteten Datensatz, der bereits für das Training freigegeben wurde – keine manuelle Triage erforderlich.
- Setzen Sie interne Nutzungsrichtlinien durch: Definieren Sie, was für die Verwendung von GenAI akzeptabel ist, und kennzeichnen und verwalten Sie es entsprechend, damit Ihre Teams standardmäßig konform bleiben.
Warum BigID
BigID ist die einzige Plattform, die die Erkennung, Klassifizierung und Kontrolle von Daten und KI vereint. Mit Data Labeling für KI können Kunden:
- Operationalisieren Sie die KI-Governance bevor Probleme auftreten
- Reduzieren Sie das Risiko von Offenlegung, Missbrauch und Richtlinienverstößen
- Passen Sie die KI-Nutzung an die Entwicklung an Frameworks und Unternehmensstandards
Sehen Sie es in Aktion
Demo anfordern von BigIDs Datenbeschriftung für KI und erfahren Sie, wie Sie die Kontrolle über Ihre KI-Pipeline übernehmen – bevor Ihre Daten dies für Sie tun. Vereinbaren Sie noch heute ein Einzelgespräch mit einem unserer KI- und Datensicherheitsexperten!
