

KI ist nur so sicher wie die Daten, mit denen sie trainiert wird. Die meisten Unternehmen verlassen sich jedoch immer noch auf rohe, ungefilterte Datensätze – gefüllt mit sensiblen, persönlichen oder regulierten Informationen. Sobald diese Daten in ein Modell gelangen, können sie schnell infizieren, verloren gehen, unbefugten Zugriff erhalten und erhebliche Compliance-Risiken verursachen.
BigID ändert das.
Wir freuen uns, Ihnen vorstellen zu dürfen Datenbereinigung für KI, eine leistungsstarke neue Funktion, die Unternehmen hilft Entfernen Sie risikoreiche Inhalte aus KI-Datensätzen, bevor sie zu einem Problem werden. Mit dieser Einführung bietet BigID Sicherheits- und Governance-Teams die Möglichkeit, automatisch redigieren oder tokenisieren sensible Daten über strukturierte und unstrukturierte Quellen hinweg – und hilft Teams beim Aufbau.
Die Herausforderung: KI-Pipelines sind Risiko-Pipelines
Unternehmen skalieren GenAI im gesamten Unternehmen – doch die meisten verfügen noch immer über keine Leitplanken für den Datenfluss in die Modelle. Dadurch entsteht ein blinder Fleck: Sobald sensible Daten in eine Eingabeaufforderung, einen Copiloten oder ein Trainingsset gelangen, ist es fast unmöglich, sie einzudämmen.
Sicherheitsteams müssen diese Daten bereinigen können, bevor sie das Modell erreichen.
Bislang war dies manuell, inkonsistent und unzuverlässig.
Die Antwort von BigID: Daten bereinigen, bevor KI sie berührt
Data Cleansing für KI löst dieses Problem, indem es Teams eine skalierbare Möglichkeit zur Vorverarbeitung von Datensätzen mit integrierter Governance bietet.
- Automatisch erkennen und klassifizieren persönliche, sensible oder regulierte Daten
- Wählen Sie redigieren oder den Inhalt tokenisieren—Erhaltung des Nutzens ohne Risiko
- Wenden Sie die Bereinigung sowohl auf strukturierte als auch auf unstrukturierte Daten an: E-Mails, PDFs, Dokumente und mehr
- Durchsetzung der Richtlinien an der Quelle, bevor Daten in Ihre LLM-Pipelines gelangen
Das Ergebnis? Sauberere Datensätze, geringeres Risiko und stärker KI-Sicherheitslage.
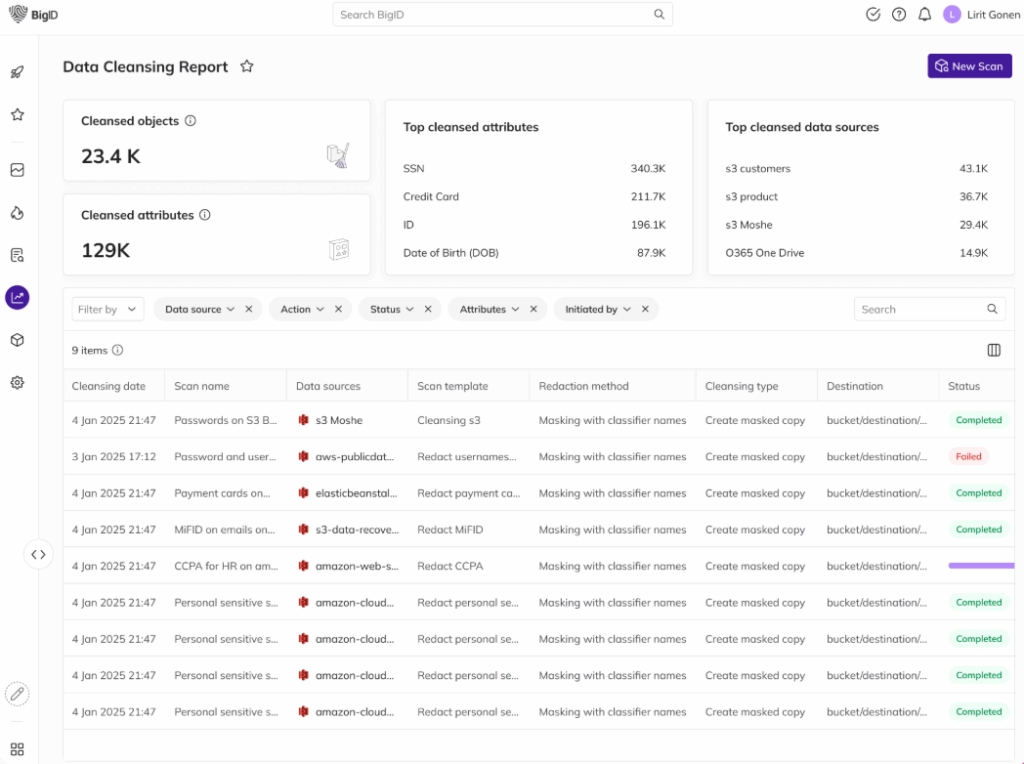
Vorteile in der Praxis
- Datenlecks verhindern: Verhindern Sie, dass persönliche und vertrauliche Informationen in KI-Ausgaben eingebettet werden.
- Schutz vor sofortiger Injektion: Minimieren Sie das Injektionsrisiko, indem Sie Eingabeaufforderungen und Quelldateien bereinigen.
- Behalten Sie den Kontext bei, nicht das Risiko: Durch die Tokenisierung bleibt die Struktur erhalten, sodass die Modelle weiterhin effektiv lernen.
- Verwalten unstrukturierter Daten: Bereinigen Sie Daten über Datenbanken hinaus – dort, wo sich die meisten vertraulichen Inhalte tatsächlich befinden.
- Beschleunigen Sie die KI-Nutzung mit Zuversicht: Geben Sie KI-Teams schnelleren Zugriff auf genehmigte, vertrauenswürdige Datensätze.
Warum es wichtig ist
KI entwickelt sich schnell – doch Sicherheit, Datenschutz und Compliance dürfen dabei nicht auf der Strecke bleiben.
Datenbereinigung für KI ist Teil von BigIDs umfassenderem Sichere Datenpipeline, und hilft Unternehmen, die Kontrolle darüber zu gewinnen, welche Daten in GenAI entdeckt, gekennzeichnet und verwendet werden. So überwinden Unternehmen blindes Risiko zu proaktive Governance– ohne Innovationen zu blockieren.
Sehen Sie es in Aktion
Möchten Sie sehen, wie Datenbereinigung für KI funktioniert? Vereinbaren Sie noch heute ein 1:1-Gespräch mit einem unserer Datensicherheitsexperten!
