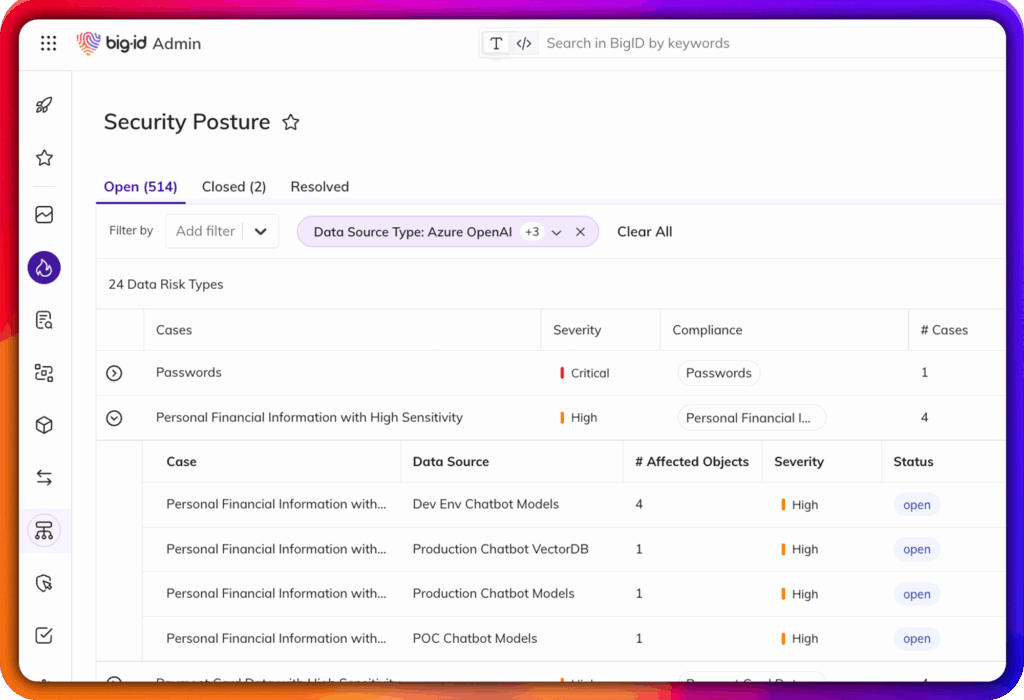
Os modelos de IA são tão bons quanto os dados que os treinam. A maioria dos fluxos de trabalho é confusa, incompleta ou não está em conformidade com as normas, colocando em risco a precisão, a privacidade e a segurança. A BigID ajuda as organizações a construir fluxos de trabalho de dados de IA seguros por meio de:
-
Classificando Dados estruturados e não estruturados (incluindo código, bate-papo e registros) por sensibilidade.
-
Categorização conjuntos de dados com taxonomias de negócios para melhor contexto
-
Catalogação com um índice de metadados unificado e pesquisável
-
Curadoria conjuntos de dados de treinamento com busca semântica para relevância e qualidade.
-
Limpeza e redigir dados sensíveis ou tóxicos antes do treinamento.
-
Verificação de conformidade conjuntos de dados em relação a regulamentações globais e políticas internas
-
Controlando Fluxos de dados em etapas com diretrizes políticas e governança