
Tourner Principes du CDMC dans Contrôles cloud mesurables
Le cadre CDMC établit des directives structurées en matière de gouvernance, de catalogage, de protection, de cycle de vie et d'architecture. Les institutions financières et les entreprises réglementées doivent démontrer des contrôles mesurables des données dans le cloud, y compris dans les environnements multicloud et hybrides.
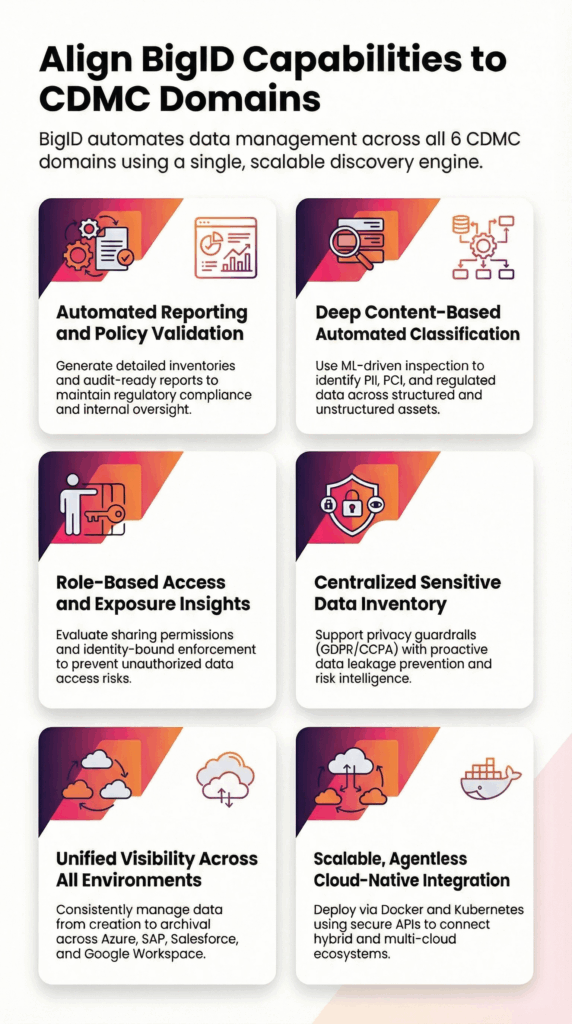
BigID permet aux organisations de :
- Découvrir et classer les données sensibles du cloud
- Attribuer la propriété et la gestion
- Surveiller les risques liés à l'accès aux données et à leur utilisation
- Appliquer les politiques de cycle de vie et de conservation
- Valider la lignée et la provenance des données
- Générer des rapports de gouvernance étayés par des données probantes
L'alignement CDMC nécessite une automatisation. BigID assure le contrôle opérationnel au niveau des données.
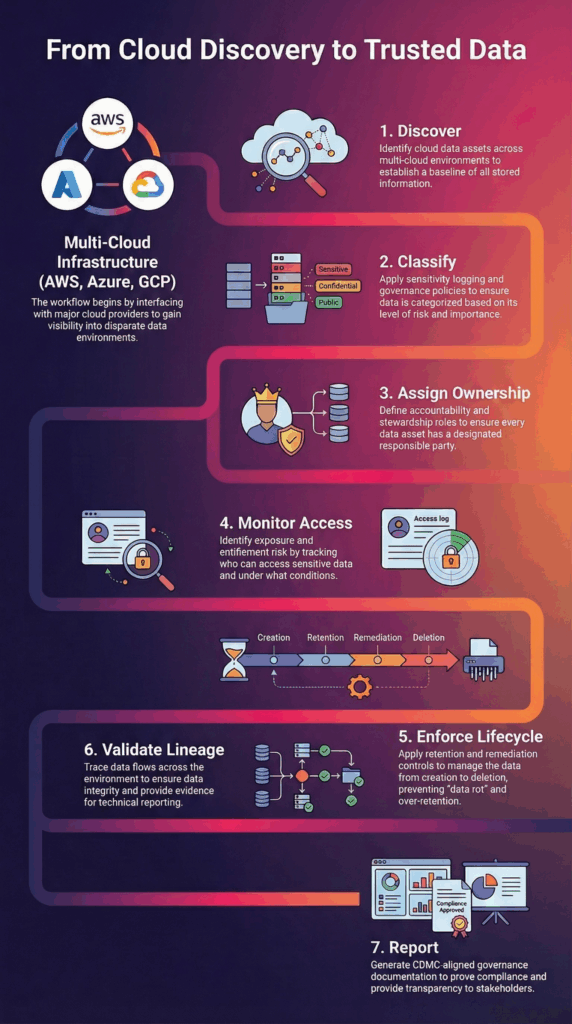
Renforcer la gouvernance des données dans le cloud Sur plusieurs clouds
CDMC accorde une grande importance à la discipline de la gouvernance des données dans le cloud.
BigID prend en charge :
- Découverte d'AWS, Azure et Google Cloud
- Visibilité SaaS et lac de données
- Déploiements natifs du cloud et hybrides
- Analyse continue des architectures cloud en constante évolution
Les organisations bénéficient d'une visibilité unifiée sur l'ensemble des écosystèmes cloud distribués.
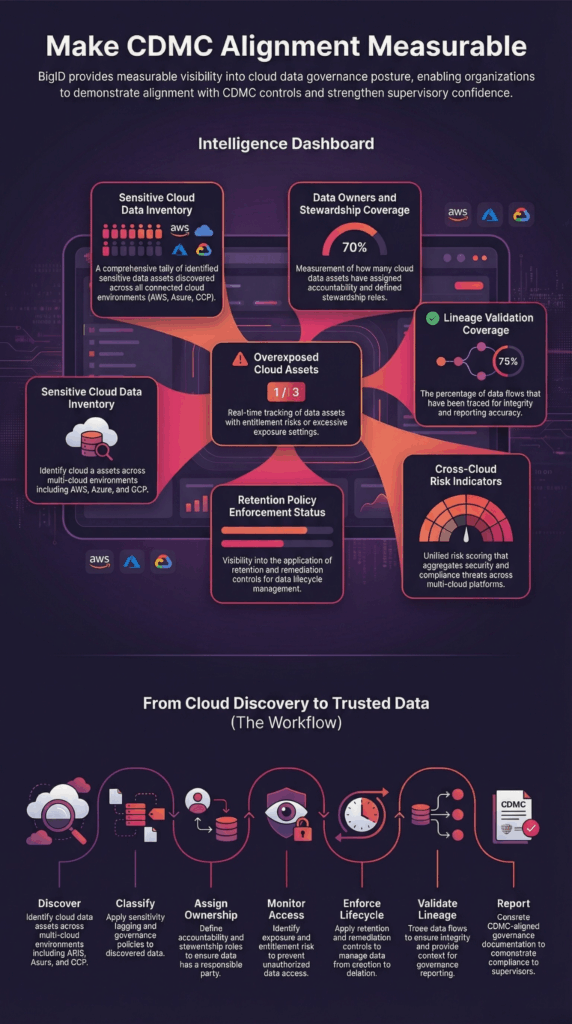
Pourquoi BigID pour l'alignement CDMC
Le catalogage manuel et la documentation des politiques ne peuvent être adaptés aux environnements cloud dynamiques. BigID intervient directement au niveau des données pour automatiser les contrôles de gouvernance conformes au CDMC.
BigID est :
- Données cloud structurées et non structurées basées sur le contenu
- Évolutif sur des architectures hybrides et multicloud
- Conçu pour la convergence de la gouvernance, de la confidentialité et de la sécurité
- Capable de s'intégrer aux catalogues d'entreprise et aux outils de gouvernance
- Conçu pour une surveillance continue du cloud
Les organisations bénéficient ainsi d'une meilleure visibilité, d'un contrôle accru et d'une gouvernance solide au sein des écosystèmes cloud.
Opérationnaliser le cadre CDMC avec confiance
Le cadre CDMC définit la norme en matière de gouvernance des données dans le cloud. BigID vous aide à automatiser la découverte, la classification, l'attribution de propriété, l'application des règles de cycle de vie et la validation de la traçabilité dans les environnements multicloud.
Ressources
Leadership dans l'industrie



