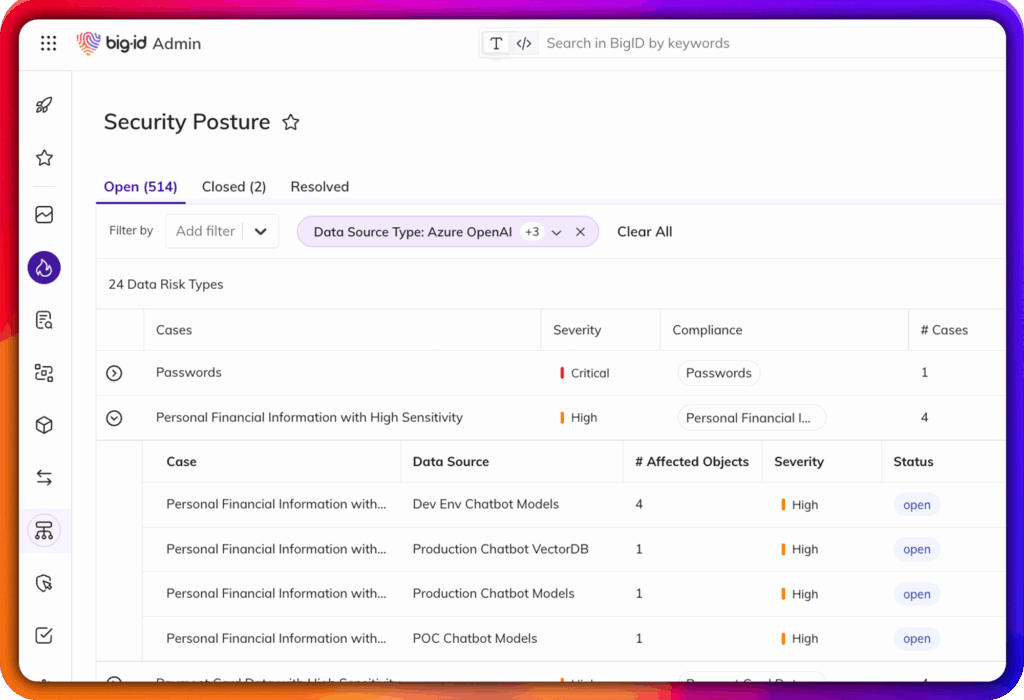
Los modelos de IA son tan buenos como los datos que los entrenan. La mayoría de los canales de procesamiento son desordenados, incompletos o no cumplen con las normas, lo que pone en riesgo la precisión, la privacidad y la seguridad. BigID ayuda a las organizaciones a construir canales de datos de IA seguros mediante:
-
Clasificación datos estructurados y no estructurados (incluidos código, chat y registros) por sensibilidad
-
Categorización conjuntos de datos con taxonomías empresariales para un mejor contexto
-
Catalogación con un índice de metadatos unificado y con capacidad de búsqueda
-
Curaduría conjuntos de datos de entrenamiento con búsqueda semántica de relevancia y calidad
-
Limpieza y redactar datos sensibles o tóxicos antes del entrenamiento
-
Comprobación del cumplimiento conjuntos de datos contra regulaciones globales y políticas internas
-
Controlador Canalizaciones de datos por etapas con políticas de protección y gobernanza