

¿Qué es Data Fabric?
Comprender la gestión de datos y la integración para el almacenamiento unificado de datos
Tejido de datos Es una arquitectura unificada que integra los procesos, datos y análisis de una organización, entre otros, en un marco interconectado. Estandariza gobernanza de datos y prácticas de seguridad en todo el mundo entornos on-prem y en la nube —incluidas las nubes híbridas y múltiples.
Los métodos tradicionales de integración de datos se basan en conexiones punto a punto y arquitecturas rígidas. Sin embargo, este marco es más flexible y dinámico. Permite que los datos de la organización fluyan libremente por todo el entorno, a la vez que garantiza... seguridad de los datos.
A diferencia de las canalizaciones ETL tradicionales, Data Fabric admite técnicas de integración de datos modernas que se adaptan a las necesidades comerciales cambiantes y entregan datos de manera más eficiente.
La arquitectura de tejido de datos permite descubrimiento de datos En un entorno distribuido. Esta arquitectura conecta diversas fuentes de datos, incluyendo almacenes de datos en la nube, bases de datos locales y aplicaciones SaaS, para crear una estructura de datos centralizada que permite el acceso, la integración y el procesamiento de datos sin interrupciones. Esta integración facilita la combinación de distintas fuentes de datos, aplicaciones e infraestructura para la virtualización de datos.
Esto, a su vez, simplifica la gestión de datos y acelera su procesamiento, lo que permite a las organizaciones obtener información y tomar decisiones informadas más rápidamente con datos específicos. Los ingenieros y científicos de datos pueden aprovechar esta arquitectura para agilizar sus flujos de trabajo y mejorar las capacidades de análisis de datos.
Además, la arquitectura de Data Fabric puede escalarse fácilmente para adaptarse al aumento de volúmenes de datos. Reduce el coste operativo y la complejidad de la integración y centralización física de los datos.
Componentes de la arquitectura de Data Fabric
Una estructura de datos no es un producto único, sino un enfoque arquitectónico basado en capacidades conectadas. Si bien cada implementación es ligeramente diferente, la mayoría de las estructuras incluyen algunos componentes básicos comunes:
Ingesta e integración de datos
Este componente reúne datos de sistemas locales, en la nube y en el borde en tiempo real a través de transmisión de datos y captura de datos modificados, o en lotes para transferencias más grandes.
Gestión de metadatos
Este proceso captura y utiliza metadatos activos Para comprender qué datos existen, cómo se relacionan con otros activos y cómo deben gobernarse. Los metadatos son la base de la automatización y la inteligencia en toda la estructura. Ayudan a automatizar la integración de datos y a reducir el esfuerzo manual.
Curación y transformación de datos
Los datos se limpian, enriquecen y preparan desde su estado original para que sean precisos, consistentes y estén listos para su análisis o uso operativo en este componente. Este proceso suele combinar datos de diversas fuentes para crear conjuntos de datos de mayor calidad.
Orquestación y entrega
Las tuberías se coordinan y los flujos de datos correctos se entregan de manera confiable a los usuarios y sistemas correctos, sin transferencias manuales ni conexiones frágiles.
Acceso y consumo
Se proporciona acceso gobernado y de autoservicio para analistas, científicos de datos y aplicaciones, de modo que los equipos puedan usar datos confiables sin crear nuevos silos.
En conjunto, estos componentes crean una estructura unificada que se adapta a las cambiantes necesidades del negocio sin necesidad de trasladar cada conjunto de datos a un único repositorio.
Cómo funciona Data Fabric
Una estructura de datos conecta fuentes de datos distribuidas a través de una capa inteligente basada en metadatos que crea una vista unificada de los datos en entornos locales, en la nube e híbridos, sin necesidad de que todo esté centralizado.
Al automatizar el descubrimiento, la gobernanza y la orquestación, la estructura puede incluir datos de fuentes estructuradas y no estructuradas y entregar conjuntos de datos confiables a usuarios y sistemas. Este enfoque permite a los equipos analizar los datos en tiempo real, manteniendo la consistencia, la seguridad y el control a medida que cambian.
¿Por qué utilizar una solución Data Fabric?
Según IBM, hasta un 68% de los datos empresariales promedio no se analizan. Además, hasta un 82% de las empresas experimentan problemas de integración debido a datos aislados y a diferentes tipos de datos provenientes de... varias fuentesSi su organización se basa en datos, esto no es ideal.
"Fabric" se refiere a la capa integrada de datos y procesos de conexión a través de todos los entornos de datos - incluyendo plataformas híbridas y multi-nube.
Con una estructura de datos cohesiva, las empresas pueden gestionar mejor sus datos. Pueden usar datos conectados, metadatos y análisis de datos para extraer el máximo valor de los datos en tiempo real. Lo más importante es que la mejor calidad de los datos hace que el análisis sea más eficaz.
Usar una estructura de datos automatizada es la mejor opción si busca una forma moderna y eficiente de gestionar sus datos. Su visibilidad cohesiva le ofrece una visión clara y completa de su panorama de datos en tiempo real. Esto simplifica el proceso de gestión de datos y acelera su procesamiento, permitiéndole tomar decisiones más rápidas y mejor informadas.
El uso de soluciones de Data Fabric facilita la escalabilidad para adaptarse a la creciente cantidad y variedad de datos que generan las empresas hoy en día, lo que les ayuda a ser más productivas, tomar mejores decisiones y mantenerse a la vanguardia de la competencia. El uso de Data Fabric también ofrece a los usuarios acceso seguro y conforme a las normas a datos de calidad adecuados para realizar sus tareas de datos.
Beneficios de un tejido de datos
Los entornos de datos modernos son complejos. Al integrar análisis continuos, tecnologías automatizadas, modelos de IA y aprendizaje automático en entornos de datos complejos, Data Fabric puede ayudar a las empresas a aumentar la confianza en los datos, tomar mejores decisiones e impulsar la transformación digital. Así es como:
Mayor accesibilidad a los datos e información
Una infraestructura unificada permite una mejor visibilidad y conocimiento de los datos. Data Fabric proporciona a su organización una visión unificada e integrada de sus activos de datos. Esto permite a las partes interesadas acceder, analizar y actuar sobre los datos de forma más eficiente y eficaz. Los responsables de la toma de decisiones obtienen información oportuna y práctica, que impulsa una mejor toma de decisiones, la innovación y la ventaja competitiva.
Mayor eficacia y agilidad operativa
Data Fabric simplifica los procesos de integración, gobernanza y gestión de datos para reducir la complejidad y las ineficiencias en las operaciones de datos. acceso a los datos El control optimiza drásticamente las iniciativas de gestión de datos, lo que permite a los equipos de gobernanza recuperar tiempo. Esto permite a su organización responder con mayor rapidez a las cambiantes necesidades del negocio, escalar las iniciativas de datos e impulsar la excelencia y la agilidad operativas.
Aceleración de la innovación y del plazo de creación de valor
Una estructura de datos le permite: proteger mejor y reducir el coste del mantenimiento y la gestión de datos, especialmente en entornos multicloud. Su empresa puede aprovechar al máximo sus activos de datos para impulsar la innovación y generar nuevas oportunidades de negocio. Democratiza el acceso a los datos y fomenta una cultura de experimentación y colaboración. Así es como la arquitectura de datos permite a los equipos innovar, iterar y ofrecer valor a los clientes de forma más rápida y eficaz.
Mayor respeto de la privacidad y la seguridad
Data Fabric incorpora sólidos mecanismos de gobernanza, seguridad y cumplimiento para garantizar la privacidad, integridad y confidencialidad de los datos confidenciales. Le ayuda a implementar controles de acceso, cifrado y técnicas de enmascaramiento de datos para proteger los datos en reposo y en tránsito. Además, Data Fabric permite a su organización garantizar el cumplimiento normativo de las leyes de privacidad de datos, como... GDPR, CCPAy HIPAA proporcionando visibilidad del linaje de los datos, su uso y la gestión del consentimiento.
Tejido de datos frente a malla de datos
La malla de datos describe otro proceso de gestión de datos que a menudo se confunde con la estructura de datos, pero aborda el problema de los datos distribuidos de forma diferente. Mientras que la estructura de datos adopta un enfoque de interconectividad universal —integrando una infraestructura continua y unificada para la gestión de datos—, la malla de datos es una arquitectura creada centralmente para su uso en silos de datos distribuidos. Sin embargo, una malla de datos no necesariamente aborda el problema de la interoperabilidad.
En última instancia, ambos enfoques hacen que los datos sean más accesibles y seguros, pero el tejido de datos por sí solo se centra en una arquitectura holística e interactiva.
Data Fabric frente a Data Lake
Data Fabric y Data Lake son dos enfoques diferentes para la gestión de datos empresariales. Aunque parezcan incompatibles, en realidad pueden coexistir sin problemas. Un Data Lake es un repositorio centralizado que permite almacenar y analizar datos estructurados y no estructurados. Por el contrario, un Data Fabric es una arquitectura distribuida que integra y comparte datos fluidamente entre múltiples fuentes y plataformas.
Los lagos de datos son ideales para almacenar y procesar grandes cantidades de datos. En la práctica, esto significa que pueden actuar como fuente primaria de datos para un tejido de datos. Los tejidos de datos, por su parte, ayudan a garantizar que estos nuevos datos sean accesibles y estén disponibles para los usuarios y las aplicaciones. Proporcionan la conectividad y agilidad necesarias para acceder a los datos y analizarlos en tiempo real.
Por ejemplo, un lago de datos podría almacenar y procesar grandes cantidades de datos de clientes, mientras que un tejido de datos podría integrar estos datos con otras fuentes, como las redes sociales, para ofrecer una visión completa del comportamiento de los clientes.
Estos lagos y tejidos de datos facilitan la creación y entrega de productos de datos. Aprovechándolos, las organizaciones pueden obtener mayores conocimientos y eficiencias de sus datos en tiempo real, garantizando al mismo tiempo que sean accesibles y estén disponibles para quienes los necesitan.
Relación entre Data Fabric y Data Integration
Una estructura de datos depende de una integración automatizada basada en IA que mejora con el tiempo. Una estructura eficaz automatiza múltiples estilos de integración, escala la gestión de datos, optimiza la distribución de datos en toda la empresa, reduce los costes de almacenamiento y maximiza el rendimiento. La arquitectura resultante:
- facilita el acceso a datos difíciles de localizar en entornos híbridos y multicloud
- elimina los silos de datos
- elimina las herramientas múltiples y manuales
- prácticas de gestión de datos preparadas para el futuro, a medida que se añaden nuevas fuentes
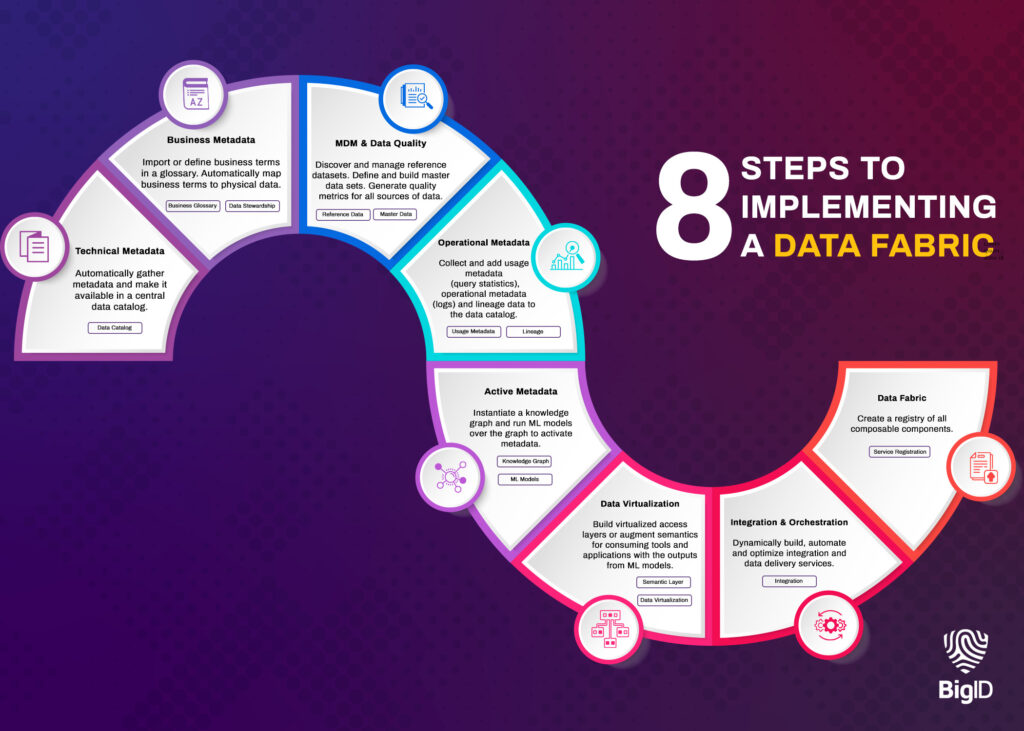
BigID y su tejido de datos empresariales: cómo funciona
BigID Presenta un enfoque semántico basado en aprendizaje automático para habilitar una infraestructura de datos para su organización. Así es como la plataforma ayuda a construir una solución de infraestructura de datos integral para asegurar la transformación digital y las prácticas de gestión de datos de su empresa en el futuro.
Cubra todos sus datos, en todas partes: Conéctate automáticamente a todos los tipos de datos -incluidos los estructurados y los no estructurados- en entornos on-prem, multicloud e híbridos.
Obtenga una vista única de los metadatos: Con una fundación discoveryBigID puede escanear todos sus datos, en todas partes, para crear un catálogo de datos unificado y una vista única de todos sus metadatos.
Clasificar datos basándose en el aprendizaje profundo: BigID se especializa en clasificación métodos que van más allá del descubrimiento basado en patrones. Clasifique automáticamente más tipos de datos con PNL y RNE - y Perspectiva de IA basado en el aprendizaje profundo dentro de la arquitectura de gestión de datos.
Intercambia y comparte datos: Permita la colaboración y el intercambio de datos entre empleados en tiempo real.
Añade contexto a los datos: Superponga metadatos técnicos, empresariales y operativos para ver los atributos y las relaciones de los datos.
Aproveche los metadatos activos para una mejor interoperabilidad: Con metadatos aumentados con ML, obtenga información de sus metadatos, capacite a su organización para tomar medidas al respecto y tomar mejores decisiones comerciales.
Vea una demostración de BigID en acción - y descubra cómo podemos ayudarle a crear un tejido de datos basado en ML.
