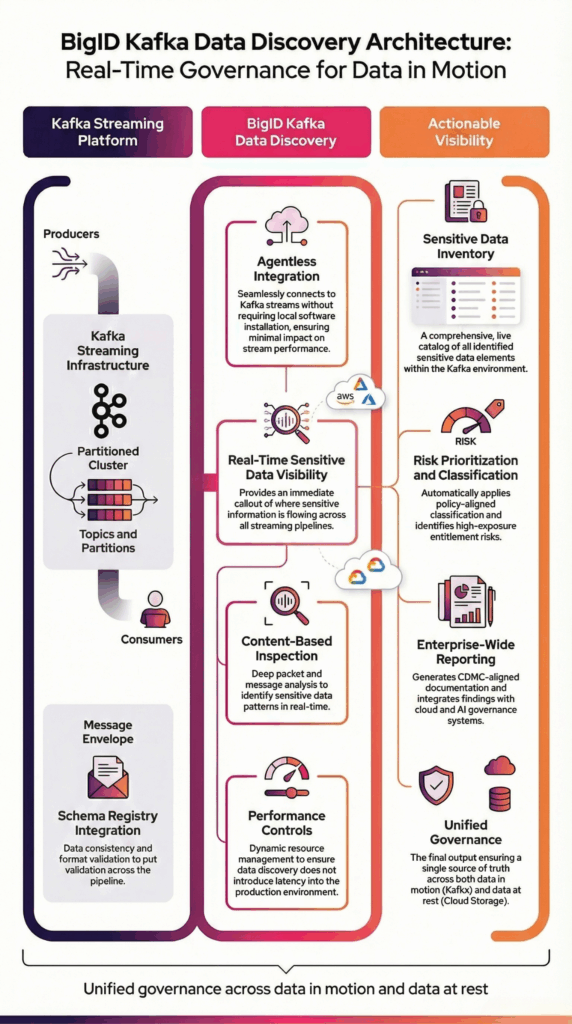
O BigID se conecta ao Kafka de forma segura usando integração sem agente para analisar dados de streaming em tópicos e partições. Ele analisa o conteúdo das mensagens para identificar com precisão informações sensíveis e regulamentadas em fluxos de dados em tempo real.
O BigID oferece suporte a:
- Apache Kafka (Núcleo)
- Kafka confluente
- Serialização Avro com integração de registro de esquemas
- Partições distribuídas e clusters replicados
O BigID realiza amostragem configurável em intervalos de sondagem para se adequar a ambientes de alto rendimento, preservando o desempenho operacional.
Os resultados da descoberta se integram às políticas de classificação corporativa, fluxos de trabalho de governança e estruturas de relatórios para fornecer visibilidade unificada em ambientes de dados de streaming e persistentes.
Essa arquitetura garante a descoberta escalável de dados sensíveis do Kafka sem interromper os pipelines de produção.