Implementando Prevenção contra perda de dados (DLP) Historicamente, a tecnologia tem sido um desafio para as organizações e equipes de segurança, pois existe uma constante batalha para encontrar o equilíbrio ideal que impeça o vazamento desnecessário de dados sensíveis da organização, sem, ao mesmo tempo, prejudicar o andamento dos negócios.
As exigências modernas de utilização de dados estão levando as organizações a reavaliarem a utilização de abordagens tradicionais de DLP (Prevenção contra Perda de Dados) e, em vez disso, a se concentrarem em resultados baseados em impacto.
Ao desenvolver uma abordagem de DLP baseada em resultados, você conquista flexibilidade e amplia suas opções de controle de dados.
(Forrester – Como construir uma abordagem de DLP baseada em resultados, 24 de novembro de 2023).
Embora as práticas tradicionais de DLP monitorem dados em trânsito pela rede, abordagens mais recentes — como Cloud DLP — Começa na origem e protege os dados armazenados e compartilhados em ambientes de nuvem. O Cloud DLP, por natureza, é orientado a resultados, pois vai além dos controles tecnológicos e abrange também processos e práticas.
Essa abordagem detecta e previne violações das políticas corporativas relativas ao uso, armazenamento e transmissão de dados sensíveis com maior eficiência, permitindo que as organizações apliquem políticas para evitar a disseminação indesejada de informações confidenciais. informações sensíveis — sem prejudicar o fluxo de negócios.
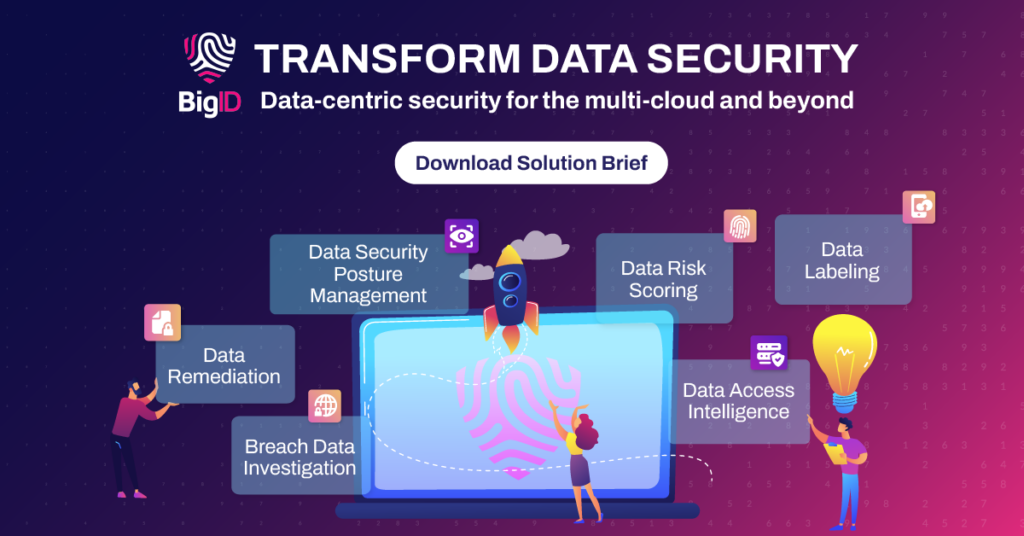
Os controles de tecnologia DLP são mais eficazes na proteção de dados organizacionais importantes quando incorporados a outros sistemas de gerenciamento de dados e segurança de dados medidas incluindo: descoberta, classificação, controles de acesso, remediaçãoUma vez que os dados sensíveis tenham sido identificados, protegidos e gerenciados, isso constitui a base para uma proteção de dados eficaz, incluindo os seguintes casos de uso:

As soluções tradicionais de DLP baseadas em rede costumam ser insuficientes e tardias quando usadas como principal controle de risco interno.
Infelizmente, com muita frequência, a mitigação eficaz do risco interno e o DLP (Prevenção contra Perda de Dados) têm sido usados como sinônimos. Isso é comparar "alhos com laranjas". O DLP é simplesmente um controle final que tenta impedir que dados confidenciais saiam da organização. Já a gestão do risco interno é uma disciplina muito mais ampla que inclui:
- Identificação de dados e indivíduos afetados
- Definindo e controlando seus dados
- Criação e aplicação de políticas
- Criando regras de engajamento
- Construindo uma equipe de risco
- Aprimorando processos consistentes
- Treinando usuários
- Os dados de monitoramento utilizam uma atividade do usuário.
A abordagem tradicional de DLP tenta impedir que dados que atendam a critérios mal definidos saiam da organização. Já o DLP em nuvem é muito mais eficaz no gerenciamento de riscos internos, pois é mais preventivo e começa identificando, classificando, protegendo e governando dados sensíveis antes mesmo que os usuários tenham a chance de acessá-los, movê-los ou enviá-los.
A descoberta e classificação de dados habilitadas por IA, a identificação de acessos indevidos e a aplicação de medidas corretivas podem reduzir o acesso a dados sensíveis em mais de 90% quando implementadas corretamente. Isso alivia bastante a pressão sobre a equipe de segurança ao tentar aplicar outras políticas, controles de segurança e DLP. Além disso, aumenta o engajamento da equipe de negócios e dos usuários, uma vez que o processo de gerenciamento de riscos internos se torna mais gerenciável.
A IA generativa exige novos controles centrados em dados para garantir a segurança e a governança dos dados.
A Inteligência Artificial Generativa (IAG) é uma tecnologia transformadora que impacta gerações. Assim como aconteceu com os computadores pessoais e smartphones, sua adoção não é mais uma questão de "se", mas sim de "quando". Por isso, as organizações estão se esforçando para proteger os dados sensíveis que podem ser utilizados nos modelos de treinamento de IAG. O principal debate gira em torno de qual o melhor momento, durante o ciclo de vida da IAG, para aplicar controles de segurança e garantir a proteção dos principais ativos de dados da organização. Os pontos possíveis são:
- Inclusão de controles de dados sensíveis na criação do algoritmo para o modelo.
- Seleção de APIs
- Consumo de dados no modelo
- Gestão do LLM
- Criação de resultados através da interface do usuário
Embora todas as etapas sejam opções lógicas, todas têm limitações. Tentar incluir controles de gerenciamento de dados sensíveis no algoritmo, ou mesmo por meio da seleção de APIs, deixa muita coisa ao acaso e pode reduzir a eficácia do modelo. O gerenciamento do LLM é difícil, pois ele geralmente é armazenado em um banco de dados vetorial como equações matemáticas, sem qualquer visibilidade direta dos dados. Por fim, os usuários têm muitas opções na etapa de saída, incluindo uma grande variedade de maneiras de acessar o modelo por meio de diferentes interfaces e navegadores.
O que resta é aplicar governança e segurança no ponto de origem dos dados que alimentam o modelo. O DLP baseado em rede não ajudará, mas uma abordagem de DLP em nuvem orientada a resultados, começando no elemento de dados, pode ajudar. Descoberta e classificação profundas e abrangentes, especialmente para conjuntos de dados não estruturadosÉ possível identificar dados organizacionais essenciais e aplicar controles para impedir que dados confidenciais, dados de privacidade e outros dados sensíveis sejam usados para preencher os modelos de lógica de vida (LLMs). A aplicação de controles proativos sobre os dados antes mesmo do início da geração de APIs reduz significativamente os riscos e torna os controles subsequentes, incluindo o DLP, muito mais gerenciáveis.

DLP ≠ Zero Trust
As abordagens tradicionais de DLP não chegam nem perto de garantir Confiança ZeroEm vez disso, o Zero Trust exige uma variedade de recursos de gerenciamento de dados combinados com controles de segurança de dados.
A fase inicial e preparatória para atingir o nível intermediário de maturidade Zero Trust inclui duas iniciativas principais para dados e dispositivos: descoberta e classificação.
(Forrester – Trace seu caminho para a Confiança Zero (Nível Intermediário), 8 de março de 2023).
Não se pode governar e controlar o que não se conhece. A descoberta de dados com IA não apenas revela o "quê", mas também o contexto e as relações entre os dados. Dados sensíveis são identificados durante o processo de descoberta, e a classificação detalhada garante que os dados e metadados sejam etiquetados de forma confiável.
Uma vez estabelecidas as etapas iniciais e contínuas de descoberta e classificação, os controles de segurança de dados podem ser aplicados de forma eficaz, incluindo:
- Governança de Acesso a Dados
- Remediação automatizada
- Gestão de Direitos
- Minimização de dados
- Navegadores seguros
- DLP
- Ofuscação (criptografia, mascaramento, redação, tokenização)
A governança do acesso a dados também começa no processo de descoberta. À medida que os dados são analisados, identificam-se acessos superexpostos e com privilégios excessivos, e a correção de violações de acesso precisa ser automatizada ao máximo. Isso é feito removendo acessos indevidos e identificando e excluindo-os. dados desatualizados A carga de trabalho para tecnologias de DLP e ofuscação é bastante reduzida.
Incorporar uma abordagem de DLP (Prevenção contra Perda de Dados) em nuvem centrada em dados a uma estratégia de Confiança Zero aprimora os controles de segurança de dados e garante uma abordagem abrangente para a proteção de informações confidenciais.
Construir uma abordagem de DLP baseada em resultados implica que ela seja apenas um dos controles de gerenciamento e segurança de dados aplicados a cenários como Risco Interno, IA Generativa e Confiança Zero. Adaptar o DLP a uma abordagem baseada em resultados garante uma estrutura de proteção de dados robusta e adaptável no cenário dinâmico de cibersegurança atual.
Para saber mais sobre como a BigID viabiliza a segurança de dados, incluindo DLP— Agende hoje mesmo uma demonstração individual com nossos especialistas.