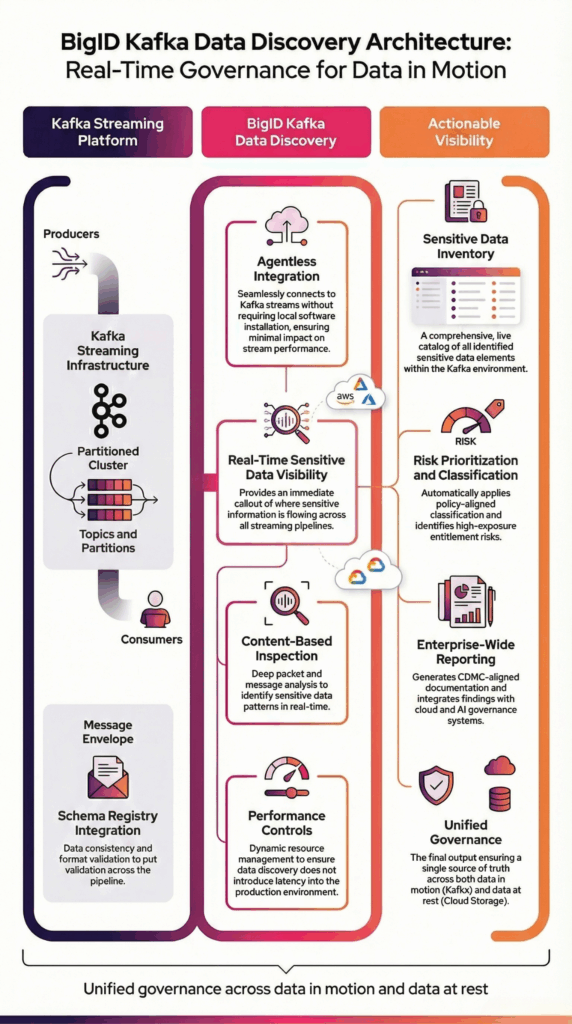
BigID se conecta de forma segura a Kafka mediante integración sin agentes para analizar datos en streaming entre temas y particiones. Analiza la carga útil de los mensajes a nivel de contenido para identificar con precisión información sensible y regulada dentro de los flujos de datos en tiempo real.
BigID admite:
- Apache Kafka (núcleo)
- Kafka confluente
- Serialización de Avro con integración de registro de esquemas
- Particiones distribuidas y clústeres replicados
BigID realiza un muestreo configurable en intervalos de sondeo para alinearse con entornos de alto rendimiento y, al mismo tiempo, preservar el rendimiento operativo.
Los resultados de descubrimiento se integran con políticas de clasificación empresarial, flujos de trabajo de gobernanza y marcos de informes para brindar visibilidad unificada en entornos de datos persistentes y de transmisión.
Esta arquitectura garantiza el descubrimiento escalable de datos confidenciales de Kafka sin interrumpir los procesos de producción.