
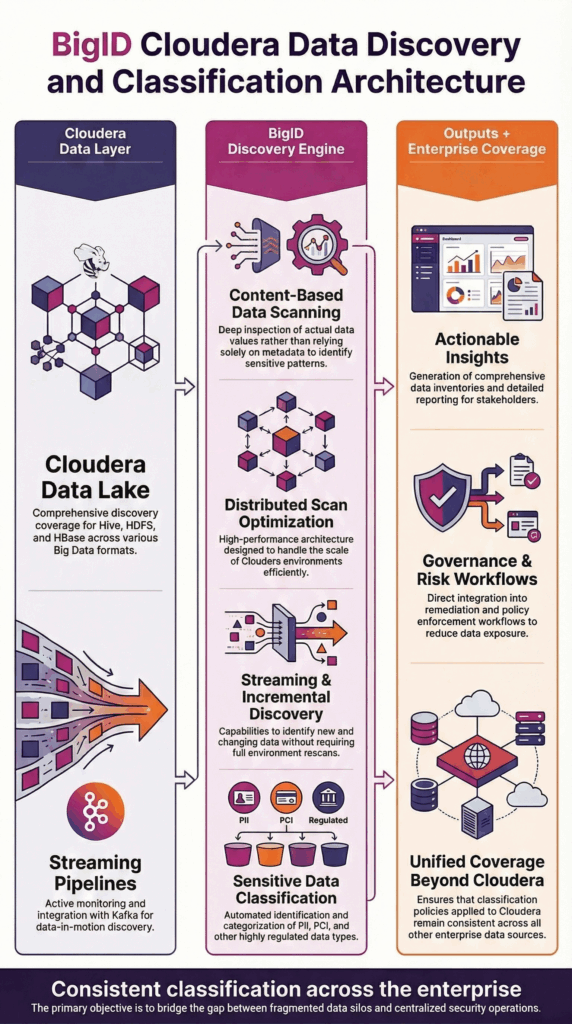
Descoberta profunda em nível de dados em armazenamento distribuído
O BigID realiza varreduras em todo o sistema:
- Tabelas do Hive
- Sistemas de arquivos HDFS
- Armazenamentos de dados HBase
- Formatos de arquivo Parquet e Big Data
- Conjuntos de dados estruturados, semiestruturados e não estruturados.
O BigID inspeciona o conteúdo real dos dados, e não apenas os catálogos de metadados, para identificar informações confidenciais em ambientes de data lake distribuídos.



