

Graças aos grandes avanços e descobertas na área de Processamento de Linguagem Natural (PLN), temos acesso a uma vasta quantidade de recursos prontos para uso. Classificadores de Reconhecimento de Entidades Nomeadas (NER)Esses classificadores estão disponíveis em muitos idiomas comuns e sua variedade está crescendo rapidamente. Existem modelos que abrangem entidades linguísticas relevantes para muitos casos de uso, prontos para uso imediato. No entanto, em muitos casos, a funcionalidade pronta para uso não é suficiente para alcançar o melhor desempenho para um uso específico devido à incompatibilidade entre os dados de produção e os dados com os quais o modelo foi treinado. Nesses casos, enriquecer os dados de treinamento com amostras adicionais melhora significativamente a precisão do modelo.
Neste artigo, discutiremos:
- Por que você deveria considerar treinar seus próprios modelos?
- O uso da aprendizagem por transferência para reduzir os custos de coleta de dados
- Anotação de dados eficaz e eficiente com aprendizado de máquina
Por que você ainda deveria considerar treinar seus próprios classificadores NER?
Ao treinarmos um modelo de aprendizado de máquina, não queremos apenas que ele modele os dados de treinamento. Queremos que o modelo tenha a capacidade de se adaptar e reagir a novos dados nunca vistos antes, extraídos de uma distribuição semelhante, mas não idêntica, àquela usada para treinar o modelo.
Por exemplo, quando construímos um modelo que visa reconhecer nomes completos em texto livre, queremos que ele seja capaz de reconhecer nomes que nem sequer aparecem no conjunto de dados de treinamento. Como? Considerando não apenas o nome em si, mas também o seu contexto.
Considere a seguinte frase: "A primeira vez que ela usou sua espada, Arya Stark tinha apenas nove anos de idade". Usando o contexto, um modelo pode prever que Arya Stark é o nome de uma pessoa, mesmo que esse nome específico não apareça nos dados de treinamento.
Outro exemplo em que o contexto desempenha um papel importante é a capacidade de distinguir entre tipos de entidades, mesmo que a palavra em si seja a mesma. Usando pistas contextuais, um modelo pode aprender que "Apple" é uma organização em um contexto, mas é uma fruta em outro.

Essa consideração do contexto é o motivo pelo qual os dados de treinamento devem ser o mais representativos possível dos dados que processaremos em produção. Um modelo treinado com documentos da BBC, onde frases na primeira pessoa são extremamente raras, provavelmente terá um desempenho ruim em transcrições de filmes. Da mesma forma, um modelo treinado com coleções de literatura provavelmente terá um desempenho ruim em textos financeiros.
O custo de treinamento de um novo classificador
A vasta quantidade de ferramentas de aprendizado profundo e bibliotecas de código aberto disponíveis hoje, como o SpaCy, nos permite construir rapidamente novos classificadores NER. A coleta e anotação de dados para um projeto como este é, de longe, a parte mais cara e demorada.
Um projeto típico requer vários milhares de documentos para construir um corpus de treinamento representativo – e geralmente leva meses para coletar e anotar todos esses documentos.
Um estudo sobre a importância e o tempo gasto em diferentes etapas de modelagem (M. Arthur Munson, Sandia National Laboratories) Mostra que a coleta, organização, limpeza e rotulagem de dados podem consumir cerca de 80% do tempo total gasto em um projeto.
Aprendizagem por transferência
É aí que entram os classificadores NER prontos para uso. Esses classificadores já são treinados em grandes conjuntos de dados de documentos, reduzindo os custos (tempo e recursos) de coleta de dados. O processo de pegar um modelo treinado e adaptá-lo aos seus dados específicos é chamado de aprendizado por transferência.
A ideia central da aprendizagem por transferência é aproveitar o conhecimento adquirido ao resolver um problema e aplicá-lo a um problema distinto, porém relacionado. Por exemplo, o conhecimento adquirido ao aprender a reconhecer nomes de pessoas também pode ser aplicado (transferido!) para reconhecer nomes de organizações.
Na prática, utilizamos um modelo pré-treinado, atualizamos a variável alvo de acordo com nossas necessidades e treinamos o novo modelo. Dessa forma, não partimos do zero, mas sim aproveitamos o aprendizado já realizado pelo modelo pré-treinado. O uso da aprendizagem por transferência reduz significativamente a quantidade de dados que precisam ser anotados por analistas humanos, geralmente de milhares de exemplos para algumas centenas.
Rotulagem auxiliada por modelo
O problema é que mesmo anotar apenas centenas de exemplos é caro e exige muitos recursos. Rotular entidades em grandes documentos de texto livre é uma tarefa difícil que requer muita concentração e está sujeita a erros humanos.
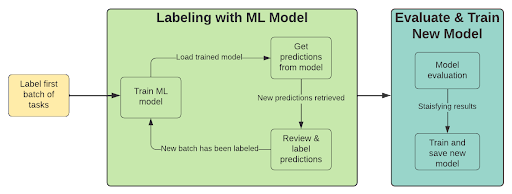
Uma maneira de reduzir o trabalho de rotulagem é combinar um modelo de aprendizado de máquina ao processo de anotação. Essa abordagem utiliza previsões do modelo para pré-anotar novos exemplos, permitindo que um humano revise rapidamente essas anotações, confirmando-as ou rejeitando-as conforme apropriado. Trata-se de um processo iterativo com as seguintes etapas:
- Rotule um lote de exemplos
- Treinar um modelo (usando aprendizagem por transferência)
- Pré-rotular com modelo treinado
- Analisar previsões com baixa confiança
- Rotule um novo lote de exemplos (escolha aqueles em que o desempenho do modelo é baixo).
- Repita a partir do passo 2 até ficar satisfeito com os resultados.
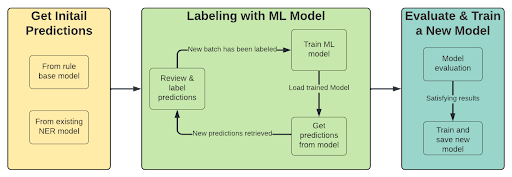
Se já tivermos um classificador NER com as entidades necessárias, a etapa inicial do processo muda. O primeiro passo é obter previsões do modelo (ou Regex) para usar essas previsões na anotação de documentos com pontuações baixas.
O processo então se torna:
- Pré-rotular com modelo treinado ou Regex
- Analisar previsões com baixa confiança
- Rotule um novo lote de exemplos (escolha aqueles em que o desempenho do modelo é baixo).
- Treinar um modelo (usando aprendizagem por transferência)
- Repita a partir do passo 1 até ficar satisfeito com os resultados.
Benefícios da rotulagem com modelo em loop:
- Eliminar em vez de reconhecer – A rotulagem de texto livre exige muita concentração por parte do rotulador, que precisa encontrar frases específicas em textos possivelmente longos. Esse tipo de tarefa é propenso a erros humanos e consome muito tempo (além de exigir conhecimento prévio da situação). Ao utilizar a pré-anotação, permitimos que o rotulador se concentre mais na eliminação de entidades rotuladas incorretamente, o que é uma tarefa muito mais fácil. Isso é feito ajustando os parâmetros do modelo para produzir previsões com alta precisão.
- Concentre-se nas tarefas importantes. – Calcular as métricas do modelo nos dados de treinamento nos permite focar na rotulagem de novos documentos onde percebemos que o modelo está com dificuldades.
- Análise de erros – A revisão de previsões falso-positivas/falso-negativas como parte do processo de anotação pode identificar problemas como ambiguidade na definição da entidade no estágio inicial do projeto.
Ao tirar o máximo proveito tanto da aprendizagem por transferência quanto da rotulagem auxiliada por modelos, podemos aproveitar a economia de tempo e recursos (humanos e computacionais) na rotulagem e no treinamento para obter modelos para nosso caso de uso de forma mais rápida e econômica.
Com o BigID, você pode personalizar seus próprios classificadores NER.e até mesmo modelos para outros idiomas, para obter uma visão contextual mais profunda e precisa, adaptada aos seus conjuntos de dados específicos. Explore e veja por si mesmo com Curso de Classificação de Dados da BigID University.