

Estrutura DLP
Prevenção contra perda de dados (DLP) aborda as preocupações com a segurança de dados por meio de políticas e regras que impedem que dados sensíveis saiam da organização. As regras são baseadas no conhecimento sobre os dados e seus metadados associados. À medida que novos tipos de dados surgiram, especificamente dados em nuvemA prevenção contra perda de dados (DLP) já não é tão eficaz como antes. Além disso, a definição de DLP tornou-se mais complexa. Felizmente, a Gartner elaborou um guia sobre como a DLP funciona, dividido em 5 etapas para implementar com sucesso a prevenção contra perda de dados.

A Gartner indica que as soluções de DLP têm escopo limitado e que provavelmente serão necessários vários fornecedores de DLP para atender às necessidades de uma empresa. Isso pode levar à inconsistência e à má interpretação das políticas. Além disso, no Guia de Mercado para Prevenção de Perda de Dados, a Gartner indica que os fornecedores de DLP dependem de serviços de classificação de dados.
As seguintes preocupações com a segurança de dados exigem mais do que o DLP (Prevenção contra Perda de Dados) por si só pode oferecer:
- Descoberta aprimorada
- Classificação
- Controle de acesso contextuall
A BigID pode melhorar significativamente o processo de DLP para essas necessidades de dados essenciais.
Por que o DLP sozinho não é suficiente
As preocupações com o DLP (Prevenção contra Perda de Dados) têm origem em suas raízes. Quando foi introduzido, o fluxo de dados dentro e fora de uma organização se limitava principalmente a e-mails. O DLP focava no corpo do e-mail, além de alguns poucos documentos de produtividade que geralmente eram anexados. Com o passar do tempo, o volume, a velocidade, a variedade e a veracidade dos dados aumentaram exponencialmente.
A BigID pode melhorar significativamente o processo de DLP para essas necessidades de dados essenciais.
Os indivíduos se comunicam por e-mail, Slack, redes sociais e outros meios. Além disso, quase todos na organização têm acesso a diversos serviços SaaS e outros serviços em nuvem e estão constantemente movimentando dados. O que antes era uma questão de criar algo simples... regras de correspondência de padrões Sinalizar dados sensíveis está longe de ser adequado. Na verdade, é praticamente impossível criar regras desse tipo para milhares de tipos de dados e bilhões de elementos de dados. Devido a esse problema, o número de falsos positivos identificados pelas ferramentas de DLP aumentou a tal ponto que dados críticos estão sendo impedidos de sair da organização, o que prejudica o andamento dos negócios. Por outro lado, o número de falsos negativos é ainda mais preocupante, pois dados realmente sensíveis não estão sendo identificados corretamente e, portanto, escapam das regras das ferramentas de DLP.
Enquanto o DLP (Prevenção contra Perda de Dados) partiu da premissa de capturar dados sensíveis assim que eles saem da organização, o BigID adota uma abordagem diferente. Você só pode criar regras para os dados que conhece. O BigID acredita que você deve saber o máximo possível sobre seus dados. Isso inclui todos os seus dados e onde eles estão armazenados:
- Estruturado
- Semiestruturado
- Não estruturado
- Dados em voo
- dados SaaS
- dados CSP
- No local
- Híbrido
Se você tiver um mapa completo de todos os dados, poderá começar protegendo primeiro os dados mais sensíveis, e não aqueles que estiverem saindo da organização no momento. Classificação de sensibilidade BigID e os controles de acesso tornam os dados sensíveis inacessíveis na maioria das situações em que o DLP seria aplicável. É aqui que o BigID pode substituir as soluções de DLP existentes ou aprimorá-las para torná-las mais precisas e previsíveis.
Abordagem do BigID para desafios de DLP
A BigID possui um extenso conjunto de conectores para centenas de fontes de dados. garante que você possa analisar até mesmo as fontes de dados mais complexas e menos conhecidas. Além disso, o BigID possui 600 classificadores de última geração prontos para uso, que utilizam não apenas correspondência baseada em padrões, mas também Classificadores de aprendizado de máquina baseados em PNL (Processamento de Linguagem Natural), Análise de inteligência artificial baseada em aprendizado profundo, identificação de documentos e classificação patenteada de análise de arquivos.
Por exemplo, a capacidade do BigID com classificadores de PNL (Processamento de Linguagem Natural) pode identificar certos números em textos corridos como sendo a idade de uma pessoa e, portanto, provavelmente informações sensíveis, mas uma ferramenta de DLP (Prevenção contra Perda de Dados) não seria capaz de detectar isso. Descoberta e classificação aprimoradas por aprendizado de máquina resulta em um registro de dados robusto e catálogo de metadados com níveis de sensibilidade aplicado aos dados. O acesso aos dados pode ser concedido ou restringido de acordo com a sensibilidade dos dados. Esse nível de proteção é mais robusto do que tentar interceptar dados sensíveis enquanto eles trafegam pelas diversas tecnologias de comunicação e transferência de dados da organização.
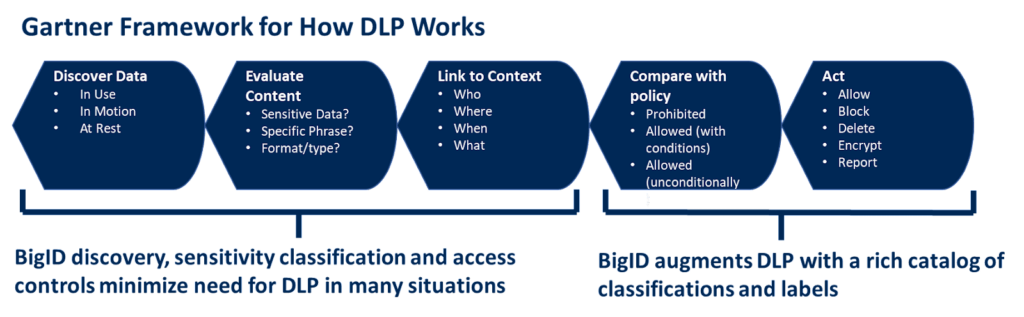
Sempre haverá espaço para DLP como uma camada adicional de proteção oferecida em conjunto com regras de acesso a dados baseadas nos artefatos de dados reais. No entanto, a BigID pode aliviar significativamente a pressão sobre as ferramentas de DLP, fornecendo um dos conjuntos de APIs mais amplos e abertos do setor. A integração do extenso repositório de metadados e dados classificados, selecionados e qualificados da BigID, com seus respectivos níveis de sensibilidade, à solução de DLP para criar e aprimorar regras reduzirá consideravelmente tanto falsos positivos quanto falsos negativos, diminuirá as ameaças internas e aliviará a carga sobre a solução de DLP.
Para saber mais sobre como Plataforma de inteligência de dados do BigID pode ajudar a preencher a lacuna entre suas ferramentas de DLP, configure um demonstração 1:1 Venha ver isso em ação conosco.