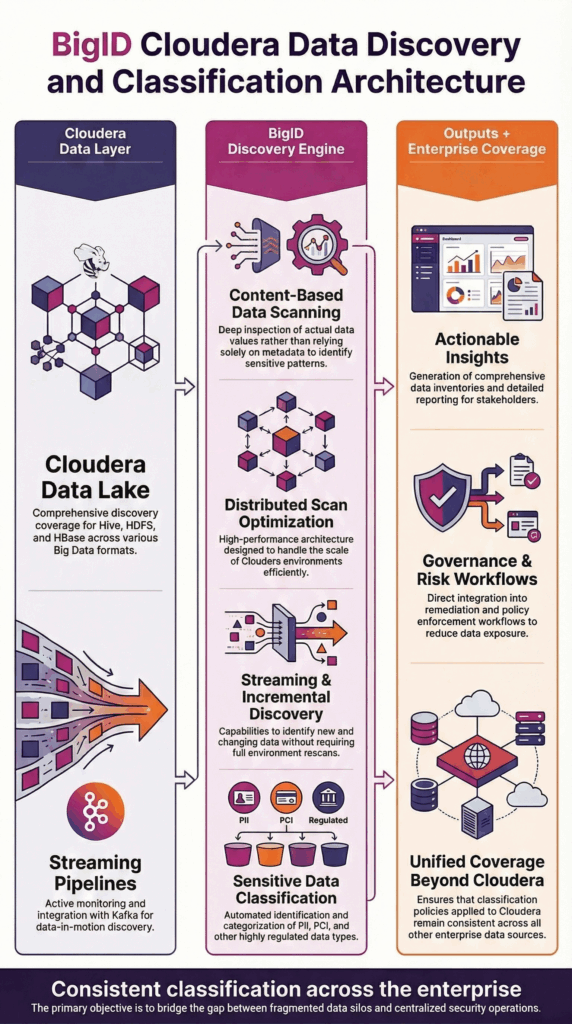
BigID se conecta de forma segura a los entornos de Cloudera para realizar descubrimientos de datos basados en contenido en Hive, HDFS, HBase y canales de streaming. Analiza los valores reales de los datos en conjuntos de datos estructurados, semiestructurados y no estructurados para identificar con precisión la información sensible y regulada.
BigID admite el procesamiento distribuido para alinearse con implementaciones de Cloudera a gran escala, lo que permite un descubrimiento escalable en entornos de lagos de datos y al mismo tiempo mantiene el rendimiento operativo.
Los resultados de Discovery se integran con políticas de clasificación empresarial, flujos de trabajo de gobernanza y marcos de informes para brindar visibilidad práctica en todo el ecosistema de datos más amplio.
Esta arquitectura garantiza un descubrimiento de datos de Cloudera preciso y a escala empresarial sin interrumpir las cargas de trabajo de producción.