

Gracias a los grandes avances y descubrimientos en el área de Procesamiento del lenguaje natural (PLN)Tenemos acceso a una gran cantidad de material listo para usar. Clasificadores de reconocimiento de entidades nombradas (NER)Estos clasificadores están disponibles en muchos lenguajes comunes y su variedad crece rápidamente. Existen modelos que cubren entidades lingüísticas relevantes para diversos casos de uso de forma inmediata. Sin embargo, en muchos casos, la funcionalidad estándar no es suficiente para lograr el mejor rendimiento para un uso específico debido a la incompatibilidad entre los datos de producción y los datos con los que se entrenó el modelo. En estos casos, enriquecer los datos de entrenamiento con muestras adicionales mejora significativamente la precisión del modelo.
En este artículo discutiremos:
- Por qué deberías considerar entrenar tus propios modelos
- El uso del aprendizaje por transferencia para reducir los costos de recopilación de datos
- Anotación de datos eficaz y eficiente con aprendizaje automático
¿Por qué debería considerar entrenar sus propios clasificadores NER?
Al entrenar un modelo de aprendizaje automático, no solo queremos que modele los datos de entrenamiento. Queremos que el modelo tenga la capacidad de adaptarse y reaccionar a nuevos datos nunca antes vistos, extraídos de una distribución similar, pero no idéntica, a la utilizada para entrenarlo.
Por ejemplo, cuando creamos un modelo que busca reconocer nombres completos en texto libre, queremos que sea capaz de reconocer nombres que ni siquiera aparecen en el conjunto de datos de entrenamiento. ¿Cómo? Considerando no solo el nombre en sí, sino también su contexto.
Considere la siguiente oración: «La primera vez que usó su espada, Arya Stark era una niña de solo nueve años». Usando el contexto, un modelo puede predecir que Arya Stark es el nombre de una persona, incluso si ese nombre específico no aparece en los datos de entrenamiento.
Otro ejemplo donde el contexto juega un papel importante es la capacidad de distinguir entre tipos de entidades incluso si la palabra en sí es la misma. Mediante pistas contextuales, un modelo puede aprender que «Apple» es una organización en un contexto, pero es una fruta en otro.

Esta consideración del contexto explica por qué los datos de entrenamiento deben ser lo más representativos posible de los datos que procesaremos en producción. Un modelo entrenado con documentos de la BBC, donde las frases en primera persona son extremadamente escasas, probablemente tendrá un rendimiento deficiente con transcripciones de películas. De igual forma, un modelo entrenado con colecciones bibliográficas probablemente tendrá un rendimiento deficiente con textos financieros.
El costo de entrenar a un nuevo clasificador
La gran cantidad de herramientas de aprendizaje profundo y bibliotecas de código abierto disponibles hoy en día, como SpaCy, nos permite desarrollar rápidamente nuevos clasificadores NER. La recopilación y anotación de datos para un proyecto como este es, con diferencia, la parte más costosa y que requiere más tiempo.
Un proyecto típico requiere varios miles de documentos para crear un corpus de capacitación representativo, y generalmente lleva meses recopilar y anotar todos estos documentos.
Un estudio sobre la importancia y el tiempo dedicado a los diferentes pasos del modelado (M. Arthur Munson, Sandia National Laboratories) muestra que la recopilación, organización, limpieza y etiquetado de datos puede tomar alrededor del 80% del tiempo total dedicado a un proyecto.
Aprendizaje por transferencia
Aquí es donde entran en juego los clasificadores NER listos para usar. Estos clasificadores ya están entrenados con grandes conjuntos de datos documentales, lo que reduce los costos (tiempo y recursos) de la recopilación de datos. El proceso de tomar un modelo entrenado y adaptarlo a sus datos específicos se denomina aprendizaje por transferencia.
La idea central del aprendizaje por transferencia es aprovechar el conocimiento adquirido al resolver un problema y aplicarlo a un problema distinto, pero relacionado. Por ejemplo, el conocimiento adquirido al aprender a reconocer nombres de personas también podría aplicarse (¡transferirse!) para reconocer nombres de organizaciones.
En la práctica, tomamos un modelo preentrenado, actualizamos la variable objetivo según nuestras necesidades y entrenamos el nuevo modelo. De esta forma, no partimos de cero, sino que construimos sobre el aprendizaje ya completado por el modelo preentrenado. El aprendizaje por transferencia reduce significativamente la cantidad de datos que los etiquetadores humanos deben anotar, normalmente de varios miles de ejemplos a varios cientos.
Etiquetado asistido por modelos
El problema es que incluso anotar cientos de ejemplos resulta costoso y consume muchos recursos. Etiquetar entidades en documentos extensos de texto libre es una tarea difícil que requiere mucha concentración y es propensa a errores humanos.
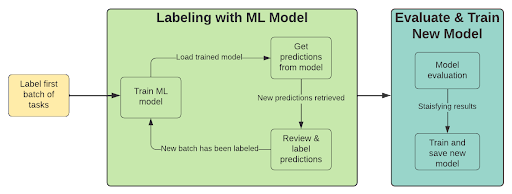
Una forma de reducir la cantidad de trabajo de etiquetado es integrar un modelo de aprendizaje automático en el proceso de anotación. Este enfoque utiliza predicciones del modelo para preanotar nuevos ejemplos, lo que permite que un humano revise rápidamente estas anotaciones, confirmándolas o rechazándolas según corresponda. Este proceso iterativo consta de los siguientes pasos:
- Etiquetar un lote de ejemplos
- Entrenar un modelo (usando aprendizaje por transferencia)
- Preetiqueta con modelo entrenado
- Revisar las predicciones de baja confianza
- Etiquete un nuevo lote de ejemplos (seleccione aquellos en los que el rendimiento del modelo sea bajo)
- Repita desde el paso 2 hasta que esté satisfecho con los resultados.
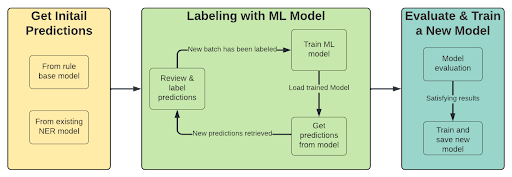
Si ya contamos con un clasificador NER con las entidades requeridas, el paso inicial del proceso cambia. El primer paso consiste en obtener predicciones del modelo (o Regex) para usarlas en la anotación de documentos con puntuaciones bajas.
El proceso entonces se convierte en:
- Preetiquetar con modelo entrenado o Regex
- Revisar las predicciones de baja confianza
- Etiquete un nuevo lote de ejemplos (seleccione aquellos en los que el rendimiento del modelo sea bajo)
- Entrenar un modelo (usando aprendizaje por transferencia)
- Repita desde el paso 1 hasta que esté satisfecho con los resultados.
Beneficios del etiquetado con el modelo en el bucle:
- Eliminar en lugar de reconocer Etiquetar texto libre requiere mucha concentración por parte del etiquetador, quien debe encontrar frases específicas en textos posiblemente largos. Este tipo de tarea es propensa a errores humanos y requiere mucho tiempo (además de conocimiento previo de la situación). Al usar la anotación previa, permitimos que el etiquetador se centre más en la eliminación de entidades mal etiquetadas, lo cual resulta mucho más sencillo. Esto se logra ajustando los parámetros del modelo para generar predicciones con alta tasa de recuperación.
- Concéntrese en las tareas importantes – calcular las métricas del modelo en los datos de entrenamiento nos permite centrarnos en etiquetar nuevos documentos donde vemos que el modelo tiene dificultades.
- Análisis de errores – revisar las predicciones falsas positivas o negativas como parte del proceso de anotación puede identificar problemas como la ambigüedad en la definición de la entidad en la etapa inicial del proyecto.
Al aprovechar al máximo tanto el aprendizaje por transferencia como el etiquetado asistido por modelos, podemos aprovechar el ahorro de tiempo y recursos (humanos y informáticos) en el etiquetado y la capacitación para generar modelos para nuestro caso de uso de manera más rápida y más económica.
Con BigID, puedes personalizar tus propios clasificadores NER, e incluso modelos para otros idiomas para obtener una visión contextual más profunda y precisa, adaptada a sus conjuntos de datos específicos. Sumérjase y compruébelo usted mismo con Curso de clasificación de datos de BigID University.