
Os catálogos de dados dependem da ingestão de metadados de bancos de dados para ajudar as empresas a organizar, descrever e, bem, catalogar seus dados — de tabelas a arquivos e esquemas. Metadados são dados sobre dados e podem ser agregados e interpretados para fornecer uma gama de informações valiosas para os negócios. Frequentemente, são integrados a dicionários e glossários de dados para iniciativas de negócios ou a metadados de propriedade de dados para governança de dados.
Os metadados por si só, porém, não contam toda a história: estão separados dos valores dos dados em si, variam significativamente de plataforma para plataforma e não conseguem identificar a quem esses dados pertencem.
Para que as organizações possam gerenciar, monitorar e proteger dados pessoais com mais facilidade, os catálogos de metadados devem ser complementados por um catálogo de informações pessoais identificáveis (PII).
Um catálogo de informações pessoais identificáveis (PII) fornece uma camada fundamental para entender como os dados estão associados a indivíduos e entidades, e utiliza metadados para adicionar contexto. Os catálogos de PII permitem que as organizações implementem as melhores práticas de segurança de dados, mantenham a conformidade contínua e automatizem políticas para ajudar a gerenciar e proteger seus dados.
Para criar um catálogo de informações pessoais identificáveis (PII), as organizações precisam de um catálogo de dados de clientes — um repositório centralizado para o inventário de dados. Um catálogo de PII oferece às organizações uma fonte única de informações confiáveis sobre o que, onde e de quem são os dados pessoais que estão sendo armazenados, processados e analisados.
4 passos para criar um catálogo de informações pessoais identificáveis (PII)
Faça um inventário dos seus dados
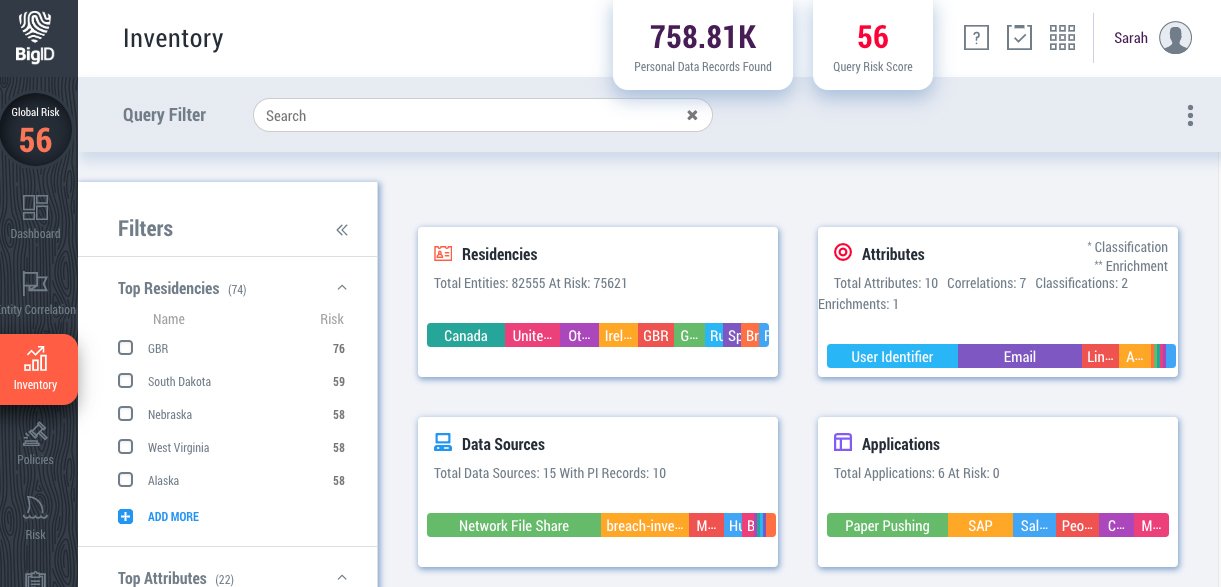
Um inventário de dados descentralizado é o primeiro passo para um catálogo de informações pessoais identificáveis (PII): as organizações precisam ser capazes de gerar um inventário dinâmico e de fácil navegação de dados pessoais sem duplicar, mover, copiar ou comprometer esses dados.
Um inventário de dados deve exibir:
- onde os registros de dados pessoais estão localizados,
- seus atributos e categorização,
- residência,
- a entidade ou indivíduo com quem eles estão associados,
- e metadados relacionados.
A descoberta de dados centrada na privacidade da BigID permite que as organizações encontrem, correlacionem e classificar Quaisquer dados pessoais – desde nomes a números de cartão de crédito e até a sua lanchonete favorita – e integrar essas informações de identidade em um catálogo de informações pessoais identificáveis (PII).
Uma vez estabelecido o inventário de dados pessoais, as organizações podem analisar detalhadamente as informações de dados pessoais e informações pessoais identificáveis, e recuperar... identidade e registros de entidades de todas as fontes de dados, e estabelecer facilmente uma trilha de auditoria.
Por sua vez, os analistas podem atribuir rótulos e tags aos atributos que os serviços upstream podem consumir para gerenciar e proteger ainda mais esses dados. Ou, no caso de catálogos que permitem a terceirização colaborativa de elementos de dados, esses termos comerciais podem ser consumidos, propagados e validados com base em uma contabilização precisa dos valores dos dados.
Correlacione seus dados
Os requisitos de privacidade (seja como uma restrição ética ou como uma exigência de conformidade regulamentar) introduzem a necessidade de compreender os elementos de dados no contexto de a quem os dados pertencem, juntamente com a necessidade de determinar se os dados são informações pessoais com base na associação a um indivíduo.
A BigID descobre dados ocultos e os correlaciona a uma identidade, revelando informações sobre identidades a partir de relações de dados. em todos os armazenamentos de dados de uma organização.
Ao correlacionar dados pessoais, as organizações obterão uma visão mais profunda de seu catálogo de informações pessoais identificáveis (PII) e associarão informações pessoais a um perfil de identidade ou entidade.
Classifique seus dados
Os dados pessoais não se limitam a informações de identificação pessoal (PII), mas abrangem também informações pessoais (PI). Classificação de dadosPortanto, é necessário ir além de expressões regulares e padrões de dados estruturados, e abranger a classificação de dados pessoais de todos os tipos.
A capacidade de classificar dados de forma automática e precisa em grande escala, em diversas fontes de dados, tanto para públicos de negócios quanto técnicos, é o principal motivo pelo qual as empresas investem em ferramentas como catálogos de dados.
A abordagem da BigID consiste em criar um modelo uniforme para o armazenamento e organização de metadados, aplicando uma classificação específica ao contexto para que as organizações possam obter mais valor de seus dados. Uma vez compilado um registro de dados a partir de valores que incorporam correlação para estabelecer a associação entre entidades, a aplicação de insights de metadados pode melhorar significativamente a precisão da classificação.
A BigID utiliza aprendizado de máquina avançado para encontrar, mapear e classificar automaticamente qualquer tipo de dado em qualquer repositório de dados, proporcionando às organizações visibilidade completa de seus dados.
As ferramentas de classificação tradicionais são otimizadas para armazenamentos de dados específicos, geralmente focando em dados estruturados ou não estruturados. O BigID, por outro lado, analisa uma ampla gama de armazenamentos de dados, desde dados não estruturados a big data, NoSQL, SaaS e muito mais, para uma visão holística multiplataforma.
Mapeie seus dados
Os mapas de dados são um requisito prático para as avaliações de impacto sobre a privacidade de dados (PIA) e um componente crítico de muitas regulamentações de proteção de dados. Eles mapeiam os fluxos de negócios em uma organização, mostrando como os dados fluem entre entidades e usuários de negócios ao longo de seu ciclo de vida.
A BigID ajuda a construir uma mapa de dados pessoais – com inteligência de dados contextuais em vez de pesquisas – para que as organizações possam analisar e avaliar mais facilmente os riscos relacionados à forma como as informações pessoais são coletadas e processadas.
Este mapeamento de informações pessoais identificáveis (PII) serve como ponto de referência fundamental para ferramentas voltadas a usuários corporativos, que podem então adicionar anotações ou curadoria de dados adicionais e identificar onde podem surgir problemas de conformidade.
Ao vincular as Avaliações de Impacto sobre a Privacidade (PIAs) a mapas gerados por varreduras contínuas, as organizações reduzem o tempo necessário para atualizá-las, ao mesmo tempo que adotam uma postura proativa em relação à conformidade com a privacidade.
O que você pode fazer com um catálogo de informações pessoais identificáveis (PII)
Assim como as empresas recorrem ao aprendizado de máquina para extrair insights de seus dados, essa mesma abordagem pode fornecer inteligência de dados, oferecendo insights sobre as relações entre conjuntos de dados e como uma organização está utilizando esses dados. O aprendizado de máquina pode ser aproveitado para inventariar, catalogar e preencher um registro de dados abrangente, automatizando a classificação por meio da análise de metadados.
Uma vez que uma organização tenha estabelecido com precisão um catálogo de informações pessoais identificáveis (PII) – e identificado, inventariado, mapeado e classificado todos os dados pessoais em seus repositórios de dados – ela poderá automatizar políticas, implementar as melhores práticas de segurança de dados e manter a conformidade contínua.
Quer ver como a BigID pode ajudar a construir o inventário de dados pessoais da sua organização? Confira nosso Guia do comprador para descoberta de dados com foco em privacidade: comece já!.