
Risco dos dados de treinamento
-
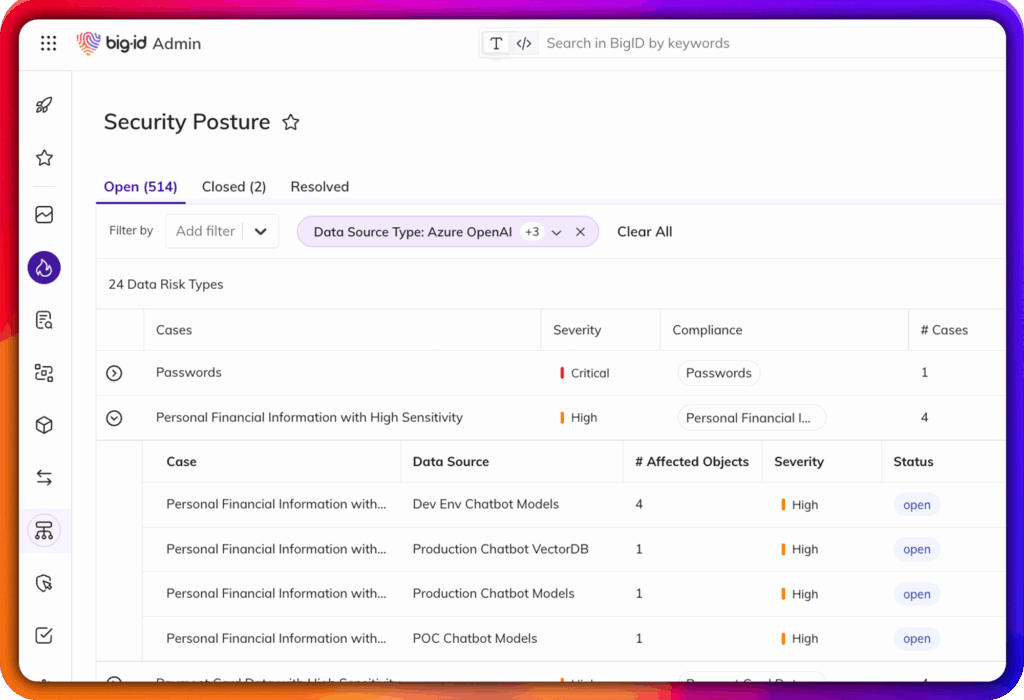
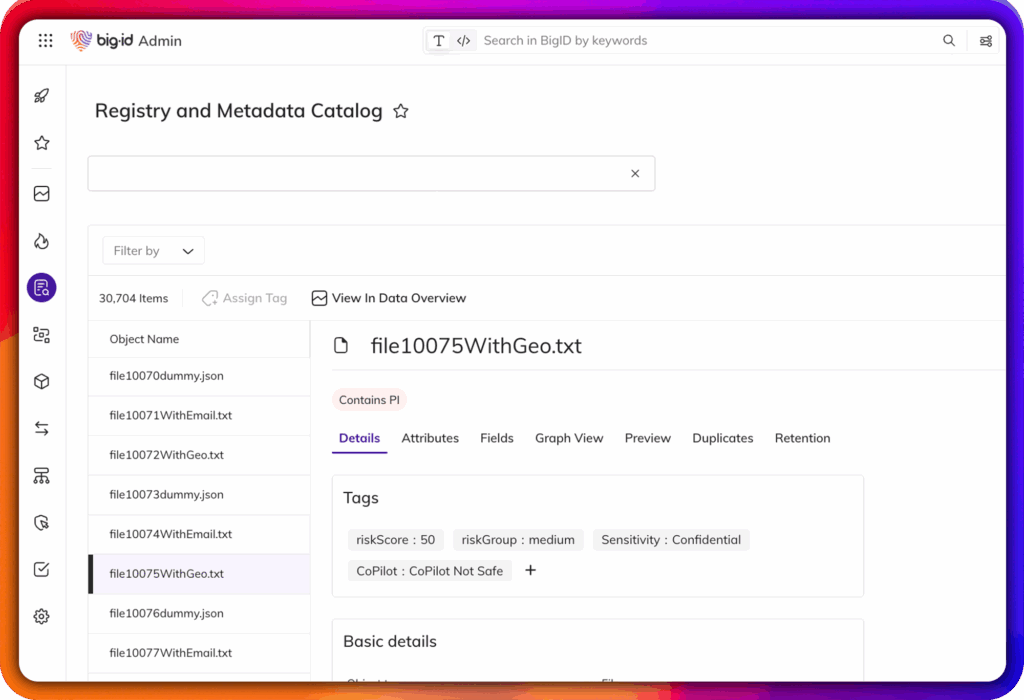
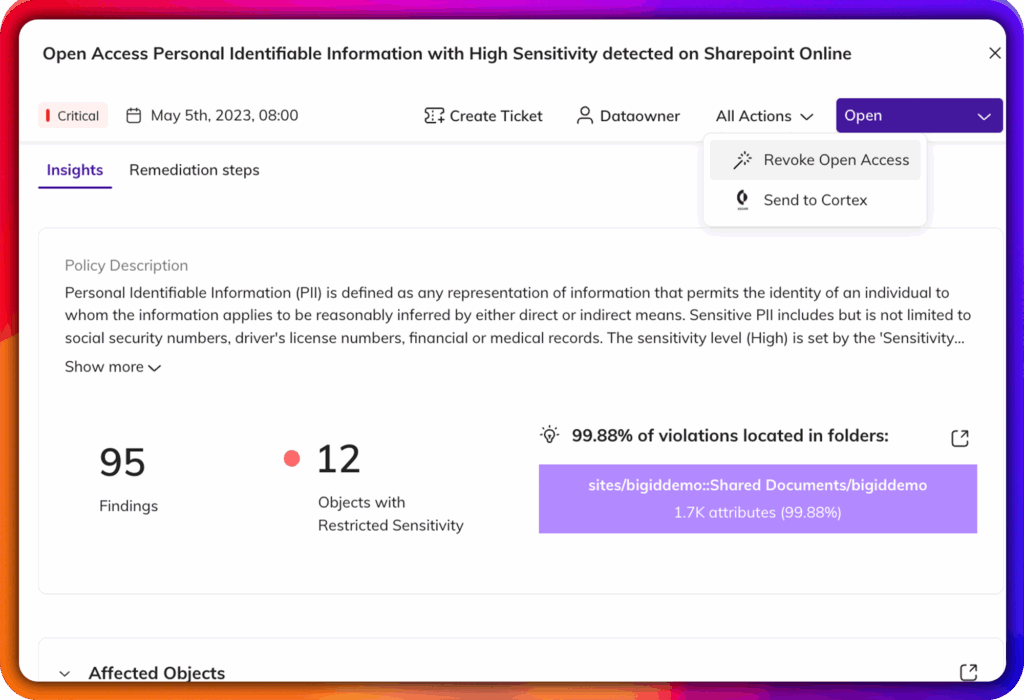
Identificar informações pessoais identificáveis (PII), informações de saúde protegidas (PHI), credenciais e propriedade intelectual em conjuntos de dados de treinamento.
-
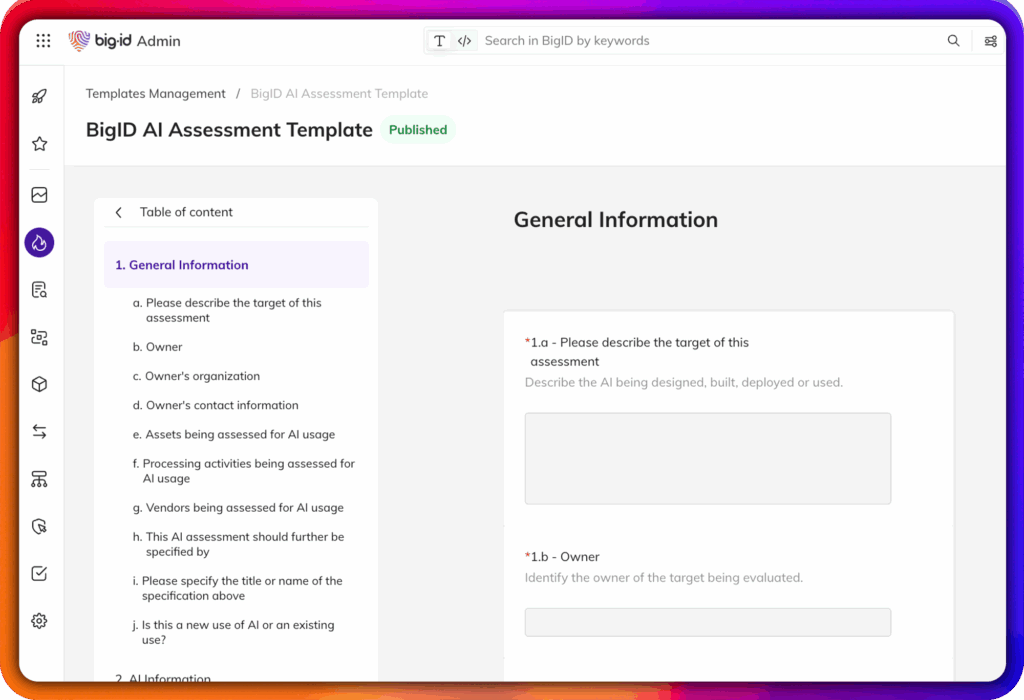
Viés de superfície, deriva e violações regulatórias antes de serem incorporadas ao modelo.
-
Mapear a linhagem dos dados brutos até as saídas do modelo para facilitar a explicabilidade.



